Back to blog
AI agent security explained
Auth & identity
Mar 29, 2025
Author: Robert Fenstermacher

AI agent security explained
How to authenticate, authorize, and defend autonomous systems
AI agents are quickly becoming the new team members in our software stacks – they schedule meetings, answer support tickets, write code, and even make product recommendations. But as we hand more responsibilities to these AI-driven agents, we also open the door to new security risks, particularly around data privacy. How do we protect our applications from malicious or compromised AI agents, and how do we safely integrate AI agents within our systems?
Traditional security models assumed a human behind each action. With AI agents, that assumption breaks down quickly.
For example, an agent might log in to your app at 3 AM, transfer funds, or change critical settings, all without direct human oversight. If done right (with proper controls), this can be incredibly powerful. If done wrong (say, by giving an agent unfettered access or sharing your password with it), the results could be disastrous. Imagine a poorly governed agent inadvertently deleting important data or an attacker hijacking an agent, potentially leading to data breaches or system disruption.
In this article, we’ll look at best practices for securing AI agents and user interactions, covering everything from authenticating agents, to authorizing them with least privilege, to defending your systems from both malicious bots and well-intentioned agents gone rogue.
Understanding the security challenges of agents
Before diving into solutions, it’s important to understand why AI agents change the security equation. In the past, “bots” were often simple scripts or scrapers with limited capabilities. They could have valid use cases but were typically seen as a security vulnerability.
Today’s AI agents – powered by large language models and advanced automation – are far more sophisticated. They can mimic human interactions on websites, interpret complex instructions, and even make decisions based on context. Businesses are also doing a lot of experimentation with AI assistants—often employing multiple agents simultaneously— that autonomously log into dashboards, pull detailed reports, and carry out tasks without direct user oversight.
This all sounds futuristic and convenient, but it introduces unique risks:
- Identity and authentication: Is a given request coming from a human user or is an AI agent acting on their behalf? If your system can’t tell, it may apply the wrong policies. An agent might legitimately log in for a user, but so might a malicious bot. You need reliable ways to identify which authorized party is behind a request.
- Over-privileged access: If an agent logs in as you with full access, it can do anything you can do. That might include actions like deleting sensitive data, making purchases, or changing configurations. Since AI agents are software, they might execute actions much faster (or more often) than a human would, potentially amplifying damage from mistakes or malicious instructions. We need granular permissioning. If an agent only needs read access to a calendar, it shouldn’t get edit permissions elsewhere.
- Lack of human judgment: Humans can (usually) spot when something looks wrong and stop what they're doing. An AI agent, on the other hand, will diligently carry out whatever task it’s given, even if the situation changes or if it misunderstands the goal. Without safeguards, an agent could, for instance, relentlessly retry an action that is failing.
- Lack of accountability and auditing: When an agent acts, how do we trace what happened? If something goes wrong, we need logs and trails tied to the agent’s identity to audit its actions.
- New attack vectors: Attackers can target AI agents directly – for example, by feeding them malicious data or prompts that cause them to misbehave and introduce new security risks (often called prompt injection or agent hijacking). If an attacker can manipulate an agent that has access to your system, they might trick it into leaking sensitive data or performing unauthorized actions. This means your defense strategy should extend to monitoring and validating agent behavior in ways it might not for a trusted human user.
Bottom line, it's important to treat AI agents as first-class entities in our security architecture. The good news is we don’t have to reinvent the wheel completely – we can extend tried-and-true concepts used for securing a human user’s account – like authentication, proper permissioning, and active monitoring.
Authenticating AI agents: giving them a secure identity
Authentication is about verifying identity: Who (or what) is this actor, and how can they prove it?
In the context of AI agents, we actually have two identities to consider: the end-user (who ultimately owns the account/data), and the agent (a third-party application acting with the user’s permission). We need to ensure the agent can prove it’s authorized by the user without the user handing over their primary credentials.
API keys and tokens
The simplest form of agent authentication is an API key or static token, where the agent presents a secret on each request to identify itself.
While easy to implement, static keys are risky. If the key leaks, anyone could act as the agent. They also don’t convey which user (if any) the agent is acting for, and are hard to granularly scope or revoke without affecting every instance of the agent.
Standard OAuth for delegation
A more robust approach is delegation through OAuth 2.0 and OIDC (OpenID Connect). OAuth was practically built for this scenario of third-party access. Instead of giving an agent your username and password, you can implement role based access control and have the agent go through an OAuth flow to get an access token for your account.
That token represents delegated authority – it says “the user Alice has allowed Agent X to act on her behalf, within certain bounds.” The agent presents the token when calling your API, and your system can verify it and grant limited access. To execute this flow, your app needs to become an OAuth provider – essentially letting the AI agent “log in” to your service on behalf of the user.
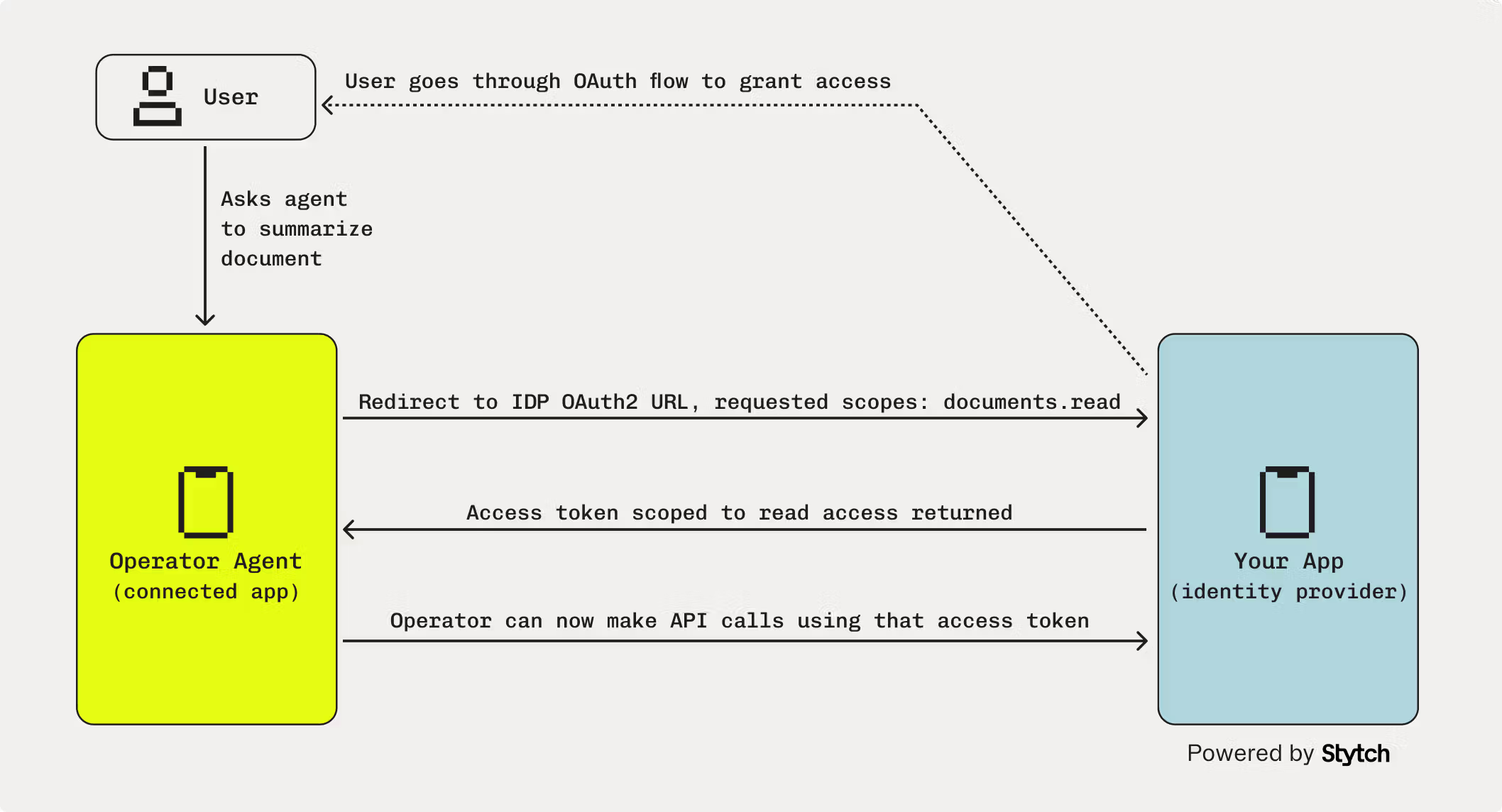
In the image above, the user invokes an AI agent to perform a task—in this case, summarizing a document. To do this, the agent must access the user’s data in your app, so it initiates an OAuth flow requesting read-only access (documents.read). The user is redirected to approve this request, granting the agent a scoped access token.
This illustrates the core of OAuth for agents: user-initiated actions, explicit consent, and limited, revocable permissions. The agent never sees the user’s credentials—only the token. If the token or agent is compromised, access can be revoked without requiring a password reset.
To summarize, if you're familiar with the typical “Login with Google/Facebook” OAuth flow then you'll notice the underlying mechanics are very similar for AI agents. You have:
- Secure user consent: OAuth requires the user to approve access via a consent screen. Instead of giving the agent a password, users see a clear list of requested permissions and decide whether to grant access.
- Token-based credentials: Once approved, the agent receives a scoped access token — not a password. If compromised, the token can be revoked without affecting the user’s main credentials.
- Granular access & revocation: OAuth tokens can be limited to specific scopes and revoked at any time. This allows for fine-grained control over what the agent can access, with support for refresh tokens when needed.
- No passwords on autopilot: OAuth keeps user credentials out of the agent’s hands. Even if the agent is compromised, the damage is limited to a single token that can expire or be revoked.
Implementing OAuth for AI agents
So how do you actually implement this? If you have engineering resources, you could build an OAuth 2.0/OIDC layer for your product from scratch – but that’s non-trivial. The OAuth standard has a lot of detail (authorization code flows, redirect URIs, token refresh, PKCE, etc.), and doing it wrong can create security holes. Instead, you can leverage existing identity providers or libraries, or use services that abstract the heavy lifting.
One such service is Stytch’s Connected Apps, which is purpose-built to turn any application into an OAuth provider with minimal effort. Connected Apps handles all the OIDC flow details for you (authorization endpoints, token exchange, validation, etc.) and lets you define, in a dashboard, what scopes and permissions are available. By using a solution like this, you don’t have to become an OAuth expert overnight – you configure a few settings and, under the hood, the steps remain standard.
Authorizing AI agents: permissions and access control
This is where we apply the principle of least privilege: give the agent the minimum access necessary for its function, no more.
Read emails | Send emails | Access Customer Data | Deploy Code | Read Metrics | Generate Reports | |
|---|---|---|---|---|---|---|
Email Assistant | ||||||
Email Assistant | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ |
Customer Support Bot | ||||||
Customer Support Bot | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
DevOps Agent | ||||||
DevOps Agent | ❌ | ❌ | ❌ | ✅ | ✅ | ✅ |
Sales Assistant | ||||||
Sales Assistant | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
This is all about defining permissions to enforce precise access controls for what an agent can do and preventing potential security violations.
Designing permission scopes for agents
A good first step is to audit your application’s functionality and categorize what an agent might do into buckets of permissions. Some categories might be:
- Read-only data access: e.g. read profile info, read transaction history, fetch a list of files.
- Standard write actions: e.g. post a comment, create an event, send a message (actions that are reversible or low-impact).
- Sensitive actions: e.g. transfer money, delete data, change password, manage other users. These might be things you never want an agent doing autonomously without user oversight, or only specific trusted agents with additional checks.
- Admin/privileged operations: likely off-limits to any agent acting as a user because these might include changing roles, accessing someone else’s data, etc.
With these in mind, you can define OAuth scopes or permissions. Using Stytch Connected Apps (or a similar solution), you can configure scopes for each connected application. For instance, Connected Apps lets you create scopes like transaction:read or transaction:transfer and tie them to what endpoints they allow.
Scope example: Let’s say you run a banking API, and you enable AI financial advisor agents. You might offer scopes: accounts.read, transactions.read, transactions.transfer, profile.write (for updating user profile). A budgeting agent might ask for accounts.read and transactions.read to analyze spending. It would not request transactions.transfer because it’s not meant to move money. If somehow it did, the user should see that and likely deny it. Even if granted, your API would later enforce that an agent with no transactions.transfer scope cannot perform a transfer.
Human-in-the-loop for sensitive actions
Even with well-scoped permissions, some agent actions — like transferring funds, sending emails, or modifying customer data — are too sensitive to happen without human review. Human-in-the-loop (HITL) controls provide a final layer of oversight when automation alone isn’t enough.
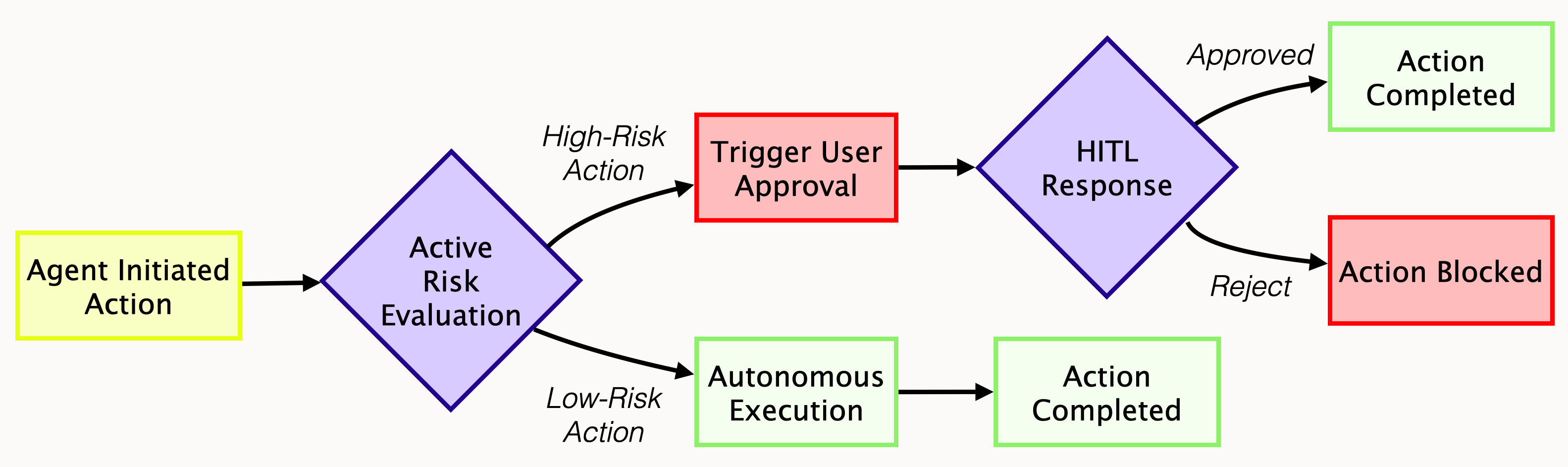
The challenge is doing this without overloading users. Interrupting them for every low-risk task isn’t scalable — especially as agents begin to chain together multiple steps across workflows. HITL needs to be flexible, context-aware, and designed for both usability and safety.
A modern approach to HITL might include:
- Push-based approvals: When an agent attempts a high-risk action, trigger a user prompt (via email or in-app) to confirm before proceeding.
- Workflow batching: Rather than prompting for every action individually, batch approvals so users can review and approve a sequence of agent steps in one place.
- Tiered scope design: Assign elevated scopes that require explicit, per-action approval, while allowing routine operations to flow uninterrupted.
These patterns allow agents to operate autonomously most of the time, while still inserting a user when it matters. Platforms like Stytch Connected Apps support these workflows through API-triggered consent and push-based approval patterns — making it easier to add HITL controls without reinventing your auth stack.
The point is, autonomy doesn’t mean unchecked power. You can decide that some things an agent attempts must loop the user or another person back in. Many systems already do this for humans (eg. via 2FA code).
Don’t forget to educate the user and provide controls
When users start delegating to AI agents, they may not fully understand what powers they're giving away. A crucial part of authorization in this context is the user experience around consent and control:
- Clear consent screens: As mentioned earlier, show clear descriptions for each scope the agent requests. Use plain language. Instead of “Scope:
read_calendar”, say “Read your calendar events”. If possible, let the user choose scopes (maybe the agent can request optional ones and the user could grant some but not others).
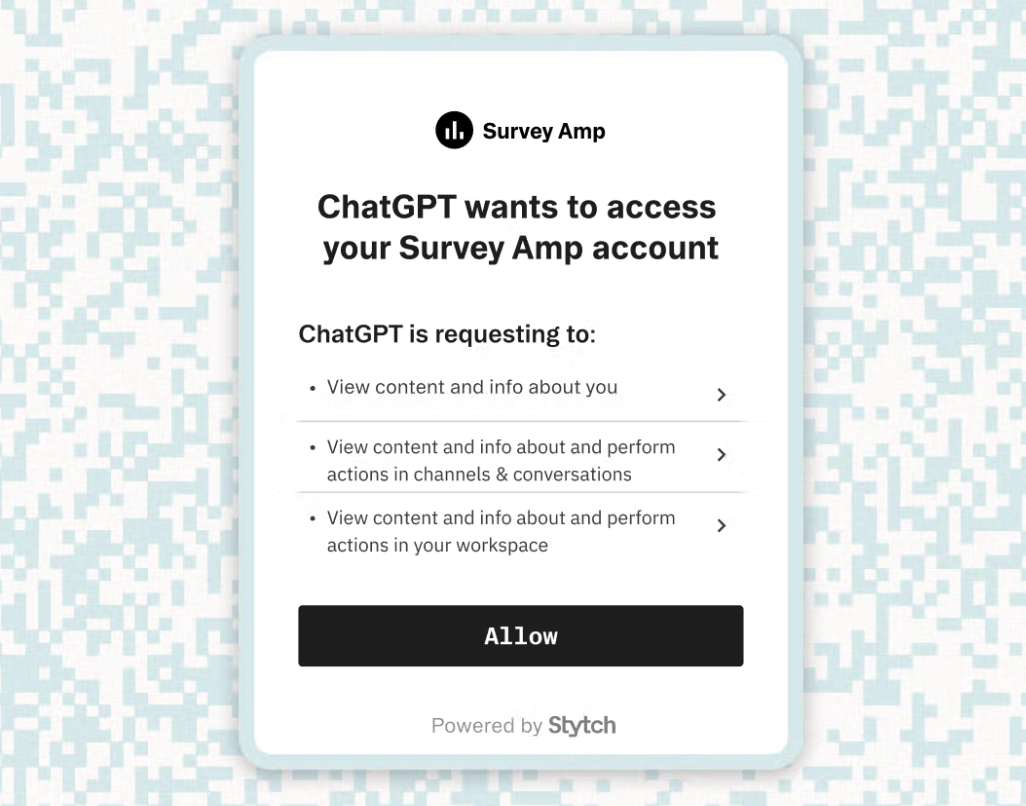
- Dashboard of connected agents: Provide users a settings page where they can see all 3rd-party agents/apps that are connected to their account. From there, allow them to revoke access easily. This is analogous to how you can see “Apps with access to your Google account” in Google’s security settings. If the user stops using an agent, they should disconnect it to clean up. If they suspect something fishy, they should be able to remove the tokens immediately.
- Scoped down data access: In some cases, you might also want to limit data exposure. For example, maybe an agent is given a
reports.generatescope. When it calls, you still might want to filter or sanitize the data it can retrieve (e.g. maybe only the last 3 months of data, not all history). This is more of an application logic consideration, but worth mentioning as part of authorization: not all data needs to be available to agents, even if they have a broad read scope. Consider segmenting or redacting sensitive fields if the agent truly doesn’t need them. - Audit trails: Make it visible to users (and admins) what actions agents have taken. “Your TwitterBotAgent posted 3 tweets on your behalf this week.” In logs, mark actions with an “via [AgentName]” tag. This transparency builds trust that, yes, the agent is doing what it was allowed to do and nothing more. If something appears that the user didn’t expect, they can investigate or revoke quickly.
By thoughtfully implementing authorization, we greatly reduce the risk of an AI agent causing havoc. But authorization alone isn’t the end – even within allowed actions, things can go wrong or be abused. That’s where defense and monitoring come into play, which we’ll tackle next.
Defending against rogue or malicious agent behavior
The job doesn’t end once an agent is authenticated and authorized. An agent might malfunction (bugs in its code or unexpected AI decisions), or an attacker might find a way to exploit it. Defending your systems means continuously validating that agent behavior stays within expected bounds — and catching issues quickly when it doesn’t.
Here’s how to build strong guardrails and real-time defenses that keep automation in check without breaking useful flows.
Know the difference: humans vs. agents
Start by making sure your system can distinguish between AI agents and human users. Tokens can carry a client ID or a flag to indicate the request origin. But you can also look at request-level signals like user-agent strings, IP ranges, or device fingerprints to classify traffic more accurately.
This matters because agents and humans behave very differently. An agent reading 1,000 messages in a second might be normal — the same behavior from a human user would be a red flag. Agents often run from cloud environments and exhibit consistent markers, while humans tend to use residential IPs and more varied browsers. These distinctions let you apply smarter risk scoring, tuning rate limits and policies based on context.
Monitor behavior, not just volume
You need to watch not just how much traffic an agent sends, but what it’s doing. If an agent suddenly accesses endpoints it never used before or behaves out of character — even if it stays within scope — that’s worth investigating.
Build behavioral baselines per agent. What data does it typically access? How often? In what patterns? Anomaly detection can be simple heuristics (“500 reads today when it usually does 5”) or more sophisticated ML models that learn usage norms over time and alert security teams proactively.
Rate limiting
Traditional rate limiting often applies the same static thresholds across the board — for example, allowing X requests per minute per token. But AI agents don’t behave like humans. They operate faster, often in bursts, and patterns can vary widely by task.
That’s where intelligent rate limiting and real time monitoring come in. Instead of looking only at volume, it examines the context of traffic: historical patterns, behavioral anomalies, device signals, and session-level information. If an agent normally makes 10 requests per minute and suddenly spikes to 100, intelligent rate limiting can spot the deviation and throttle or challenge the traffic accordingly.
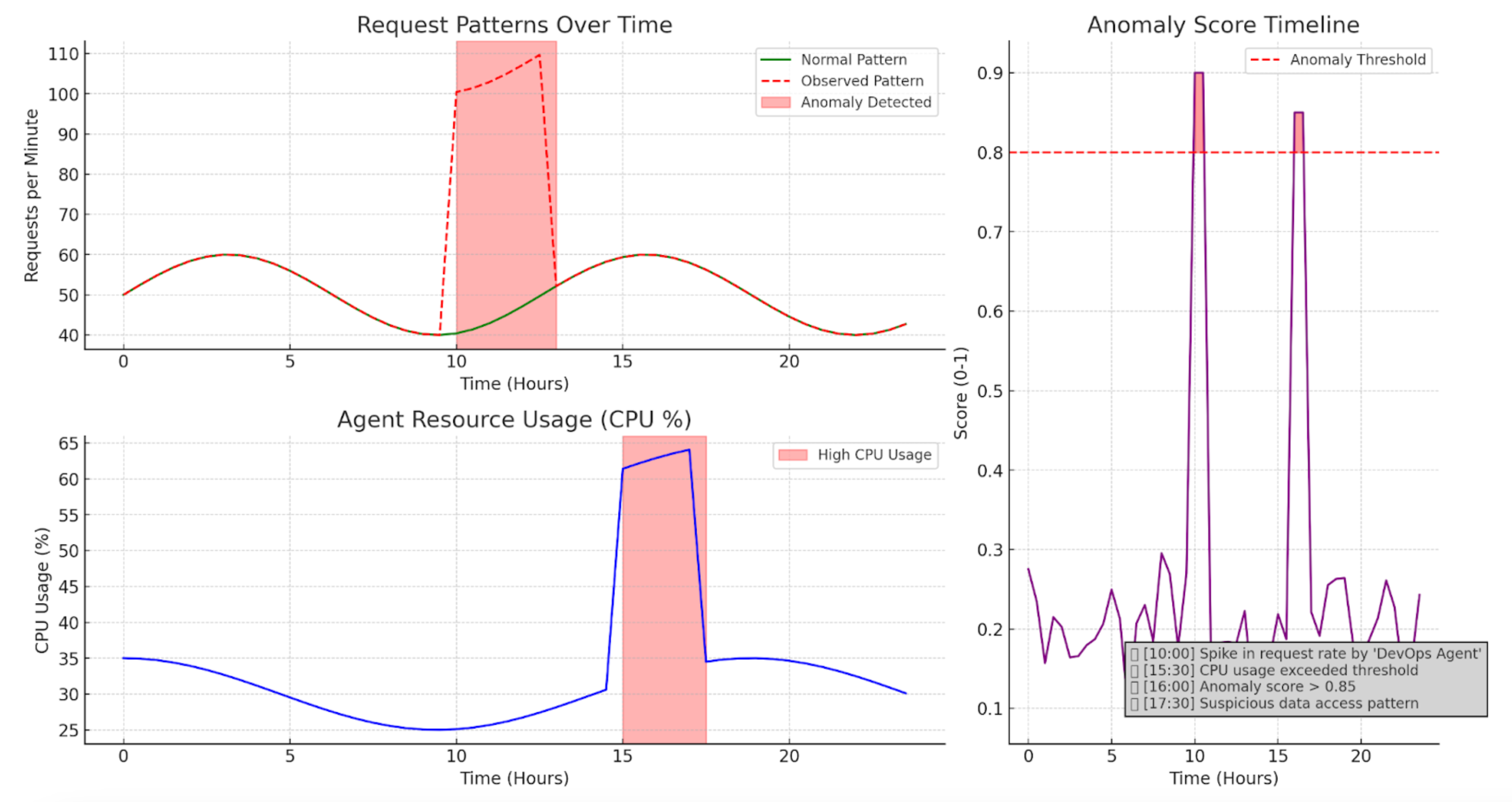
This allows you to block abuse — or halt runaway agents — without breaking legitimate usage. Some providers, like Stytch, offer Intelligent Rate Limiting out of the box with support for behavioral baselines and dynamic thresholds.
Device fingerprinting
If the agent is interacting through a UI — for example, as a browser-based copilot or script — device fingerprinting (with tools like Stytch device fingerprinting) can catch abnormal access. Signals like IP, OS, and browser type help flag when a token is being reused from a suspicious environment.
Advanced fingerprinting methods like from Stytch can now leverage supervised machine learning models trained on global datasets to detect and assess new or suspicious device types. For example, when an unfamiliar browser identifies itself as Chrome, these ML models can automatically evaluate it against all known Chrome versions to determine its validity and risk potential.
If the fingerprint suddenly changes or demonstrates other suspicious behavior, you can prompt for additional verification or block the session entirely.
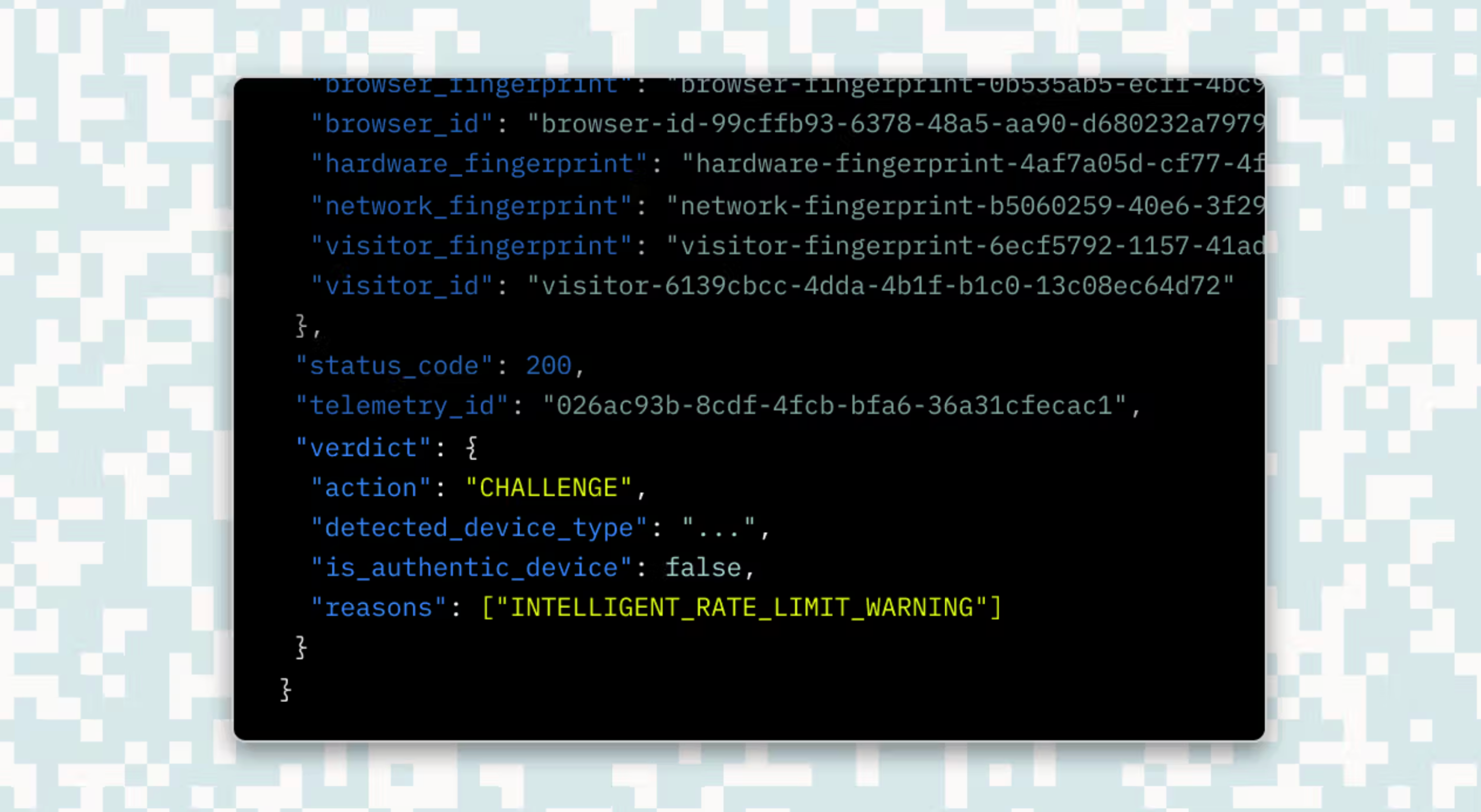
In server-to-server contexts, where device fingerprinting isn't applicable, you can continue to use infrastructure-level signals like cloud provider metadata, IP allowlists, and environment attestation.
Log everything — and use it
You can’t defend what you can’t see. Log every agent request with as much detail as possible — the token used, the endpoint called, the IP, the fingerprint, the associated user or client ID. Distinguish between human and agent activity at the logging layer so you can easily trace incidents.
Set up alerts for:
- Access to high-risk or rarely used endpoints
- Sudden spikes in request rate
- Requests coming from a new or unexpected fingerprint
- Repeated token failures or malformed requests
These signals — especially when combined — help surface issues before they turn into broader incidents.
Build a layered response model
When issues arise, you want overlapping security measures and defenses. If a token is compromised and used from a new environment, fingerprinting might catch it. If that fails, behavioral detection flags the anomaly. If the usage spikes, rate limiting slows things down. Logs and alerts help you confirm and respond quickly — ideally by revoking access before any real damage occurs.
This same layered approach works for unintentional issues too. If an agent enters an infinite loop after a bad update, your monitoring stack can catch the spike and shut things down until it’s resolved.
Best Practices and Future Considerations
AI agent security is still evolving — but the fundamentals hold. By applying proven patterns from human identity management and adapting them to the agent context, you can stay ahead of both misuse and emerging threats.
Here's a summarized set of principles to guide your strategy:
1. Don’t hard-code secrets
Agents should never store long-lived passwords or API keys in code or config. Use a secure secrets manager to prevent data leakage and rotate credentials regularly. Better yet, rely on OAuth flows to issue scoped, short-lived tokens on demand.
2. Use established OAuth and OIDC standards
These protocols are mature, widely supported, and well-understood. They allow you to delegate access safely and revoke it cleanly. Rather than inventing custom schemes, lean on open standards. Tools like Stytch’s Connected Apps can make implementing these flows significantly easier, especially if you're enabling user-granted agent access across many clients.
3. Monitor continuously
Treat AI agents as persistent service actors, not set-it-and-forget-it integrations. Log their actions, monitor behavioral baselines, and apply real-time anomaly detection. If you already operate a SOC or security monitoring stack, fold agent activity into it.
4. Build in emergency off-switches
Design your systems so that you can revoke access instantly. This might include an admin dashboard to revoke agent tokens, an automated response to detected anomalies, or a manual API endpoint that allows users or operators to cut access when things feel off.
5. Plan for threat evolution
Prompt injection and token theft are just the beginning. As agent capabilities grow, new risks will emerge —including malicious inputs, model manipulation, impersonation, and abuse of delegated authority. Keep up with security research and threat intelligence. Treat your agent security model as a living document, not a one-time setup. As AI systems become increasingly interconnected, securing the interactions between multiple autonomous agents will become even more critical.
6. Help users stay informed and in control
Give users visibility into their authorized AI agents and let them easily revoke access. Be clear about what an agent can do — both at consent time and in account settings. Offer guidance on best practices, like avoiding password sharing or limiting agent scope.
Conclusion
The rise of autonomous agents brings a mix of excitement and security concerns. As developers and engineers, our job is to harness the benefits of these agents without compromising on safety. The good news is we’re not starting from scratch – we can borrow many of the same concepts that secure human-to-app interactions and apply them to AI agent interactions. By authenticating agents with strong, delegated credentials (and features like Connected Apps for easy OAuth setup and management), authorizing them with careful scopes and limits, and vigilantly monitoring their behavior, with optionality for human intervention, we can enable autonomous systems and protect our applications and users.
In practice, implementing AI agent security can actually improve your overall security posture. It forces you to clarify access controls, audit trails, and data security practices, which benefits all users (human or AI). And it sends a message to your customers that you take security seriously, even as you embrace new technology.
AI agents will likely become even more capable in the coming years. By integrating them responsibly—with a solid security framework to manage risks—you’ll be better positioned to leverage their full potential.. So, go ahead and welcome our new AI helpers, but make sure to lock the doors, set the ground rules, and keep an eye on things. With the right approach, you can enjoy the productivity gains of autonomous agents while firmly keeping control of your agent systems' security.
Build with Stytch
APIs and SDKs for authentication, authorization, security and fraud prevention

Authentication & Authorization
Fraud & Risk Prevention
Resources
Community
© 2020-2026 Stytch. All rights reserved.