Back to blog
If an AI agent can’t figure out how your API works, neither can your users
Auth & identity
May 19, 2025
Author: Reed McGinley-Stempel

LLM-powered agents are beginning to look a lot like tireless junior developers. Hand them an API along with the docs and they’ll diligently read the reference, issue a request, parse the error, adjust parameters, and try again and again—on loop—until something works.
Frameworks like LangChain and OpenAI function-calling helpers, as well as agents like Cursor, Claude Code, OpenAI Codex, and Codename Goose, make that cycle even easier to wire up and follow.
But raw persistence of an agent isn’t always enough. The moment your API’s developer experience falters—an outdated example, a vague 400 payload, an undiscoverable required field—the agent stalls out. That stall is diagnostic. If an algorithm with perfect patience and zero ego can’t figure things out, then a human developer on a deadline is almost certainly hitting the same wall.
That symmetry can be a powerful lever. Fix the friction points that trip up agents, and you clear the path for every user, silicon‑ or carbon‑based, to have a great experience using your API.
Quick walk-through: how AI agents work with APIs
Most agent frameworks follow a ReAct cycle that interleaves reasoning and action, all intended to mirror human problem-solving.
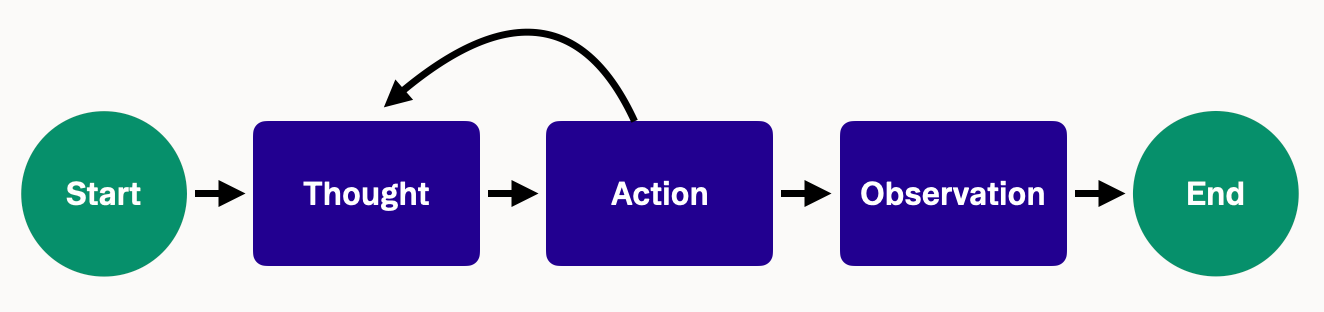
Give the agent a task (e.g. “List open PRs”) and a set of tools (e.g. the GitHub /pulls endpoint plus API docs), and it will iterate exactly like a human. It will consult the reference, fire the HTTP call, inspect the JSON or error, tweak its approach, and loop until it lands a 2xx response.
To walk through a quick example:
- Thought: “I need to create a new user via this API. Let me see… The docs show an endpoint POST /users.”
- Action: Call POST /users with the data it thinks is required (say, it provides a JSON with an email and password).
- Observation: The API returns 400 Bad Request. (Uh-oh, something’s wrong.)
- Thought: “The error is just ‘Bad Request’ with no details. I’m not sure what’s missing. Maybe I forgot a field? The docs weren’t clear about required fields. Let me guess and add a name field.”
- Action: Call POST /users with email, password, and name.
- Observation: This time it returns 201 Created – success!
In this case, the agent got lucky after one blind retry, but it was working in the dark because the error said nothing and the docs never called out the required name field. A human developer would have hit the same wall—just with more frustration and a slower iteration cycle.
When breadcrumbs do exist, agents eagerly follow along. They parse code samples, follow embedded links, and can even load documentation directly—provided it's integrated via a standardized interface such as an llms.txt file. Frameworks and tools like LangChain's mcpdoc or Mintlify facilitate this by auto-generating structured documentation that agents can parse. Agents can also incorporate hints from error payloads directly into reasoning steps. Without these clear signals, the agent quickly runs out of options.
So the success rate of an LLM agent can be a direct reflection of the clarity of your docs and error design. If the agent can’t figure out your API, odds are a human developer is stuck at the same breakpoint.
When poor API UX derails everyone
The same usability gaps that frustrate human developers—scattered docs, cryptic errors, quirky naming—throw an LLM into a tail-spin.
Start with docs
This should come as no surprise. If critical details are split between a marketing page, a stale forum post, and a 3yr old PDF, the agent won't magically stitch them together. It sees only what you feed it. Required parameters that live in a buried Changelog or a comment thread simply don’t exist from the model’s perspective. Humans feel the same pain, just more slowly.
Surface clear, detailed error payloads
An LLM consumes exactly what your API returns. Providing nothing beyond a bare HTTP status and generic code forces the agent into guesswork, potentially triggering endless retry loops.
For example, one team integrating an agent discovered a 422 response with no body text caused perpetual retries. By explicitly surfacing the error message "missing required field 'first_name'", they immediately enabled the agent to self-correct and succeed.
On the other hand, vague messages like "400 Bad Request" don't give actionable direction to either agents or humans. Clear, descriptive errors—like "expiry_date must be in YYYY-MM-DD format"—allow the agent to instantly parse the hint, regenerate its call, and move forward without interruption. Without these informative breadcrumbs, progress just stops.
Address consistency gaps
LLMs are world-class pattern detectors. They learn your casing, pluralization, and resource hierarchy in a few shots. Deviate once—user_id here, userId there—and the model may treat the second field as unrelated data. Humans might curse under their breath and move on; the agent quietly corrupts its prompt chain or mis-routes data... then spirals.
Two vignettes
To illustrate the impact of good vs. bad API UX, we can compare two scenarios of an agent interacting with a hypothetical API.
1: Guessing in the dark
Thought: Need to create an order. Docs show example curl; let's try it.
Action: POST /orders {"item": "Book"}
Obs: 400 Bad Request
Thought: No detail provided. Maybe quantity is required?
Action: POST /orders {"item": "Book", "quantity": 1}
Obs: 400 Bad Request
Thought: Still failing. Is the endpoint wrong? Another required field missing? I'm stuckThe agent sprawls, trying random tweaks—exactly what a rushed developer would do after copy-pasting a broken example.
Scenario 2: Failing Toward Success
Thought: Goal is `POST /orders`. Docs say item_id and customer_id are required.
Action: POST /orders {"item_id": "12345"}
Obs: 400 Bad Request – missing required field "customer_id"
Thought: Right, add it.
Action: POST /orders {"item_id": "12345", "customer_id": "999"}
Obs: 201 Created {"order_id": "ABC123", ...}One clear error message turns a dead end into a single iteration. The difference in time-to-success (seconds vs. minutes) comes directly from clearer docs and more context-rich errors. Fixing the documentation, tightening the schema, and writing explicit errors isn’t AI polish; it’s basic DX hygiene that you can no longer ignore.
Agents highlight what humans struggle with
When an agent stumbles, it doesn’t hide the evidence. It dumps a log of every consideration, tool call, and error it saw on the way down. Reviewing that log is like replaying a new developer’s first session—you pinpoint exactly where the trail goes cold instead of guessing.
Because the agent relies solely on what you expose—docs, examples, errors, etc—it offers noise‑free feedback. What a person might improvise or Google; an agent can’t. If it stalls, your onboarding material fell short. That’s why teams now talk about Agent Experience (AX) as the next DX frontier: the fundamentals—clear reference, solid examples, consistent patterns—remain the same, but an LLM ruthlessly exposes and logs any gaps.
Think of it like front‑end testing. Just as Selenium scripts click through your UI to catch regressions, an LLM agent “clicks” through your API in sequence. If that automated “Hello World” breaks in CI, treat it as a failing test case—you’ve caught a broken onboarding path before real users did.
Agents as practical DX smoke tests
As you iterate on your API, it’s easy for small changes to slip through and break the critical first‑use path. Rather than waiting for a support ticket or forum post, you can enlist an AI agent to act as a nightly smoke tester. By automating your “hello‑world” flow—think create user → log in—you gain immediate visibility into regressions, long before customers bump into them.
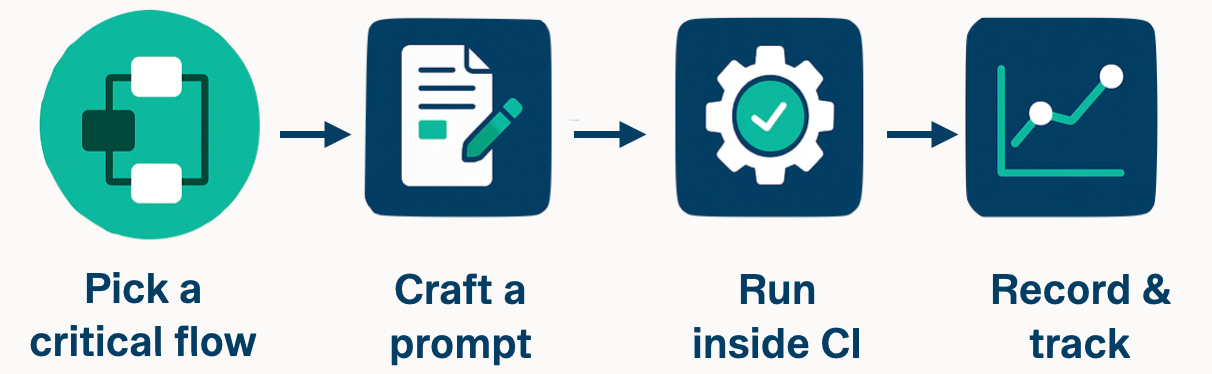
- Pick a critical flow. Define your golden path, such as creating an account and authenticating.
- Craft a tight prompt. Supply just enough documentation so the agent knows which endpoints to call and in what order.
- Run inside CI. Use deterministic settings (e.g., temperature=0, cap at 3 retries) to execute the agent on each pull request.
- Record & track. Surface three key metrics—pass/fail, retry count, and time‑to‑first‑success—in your CI logs or an evaluation dashboard.
A small fintech team ran this play and caught a missing email_verified flag during a pre‑release smoke test, fixing the issue before any customers noticed.
To implement this in your stack, consider:
Tooling selection | Why it works | |
|---|---|---|
Local sanity check | ||
Local sanity check | OpenAI Python SDK | Quick, ad‑hoc verification |
CI‑gated flow | ||
CI‑gated flow | LangChain agent + PyTest | Captures full trace and asserts pass |
Trend dashboard | ||
Trend dashboard | LangSmith or OpenAI Evals | Visualizes pass/fail and retry trends |
You can run a golden‑path test on every PR and schedule broader agent suites against a staging sandbox nightly (or reset fixtures to avoid state bleed). This type of loop keeps your core onboarding green and gives you confidence that any integration will stay solid.
Building APIs that are friendly to agents and users
Improving your API’s developer experience for AI agents doesn’t require an entirely separate playbook from improving it for humans. In fact, the needs overlap almost 100%. Here are some best practices – none of them brand new ideas, but newly validated by agent-based testing – that make your API easier to learn and use for all parties involved:
1. Provide consistent, predictable design
Consistency is king. Use the same patterns everywhere—endpoints, parameter names, response shapes. If collection routes are plural (/users, /orders) but detail routes are singular (/user/{id}), don’t slip in a rogue /users/{id}. If your payloads are snake_case, never sneak in a camelCase field.
Both humans and LLMs internalize these conventions almost immediately. After five calls that follow one rule, the sixth is assumed to follow it too; any deviation becomes a silent trap. Bottom line: a solid API foundation built on predictable, consistent patterns is the single biggest lever for an AI-first developer experience. Consistency trims away special cases, reduces onboarding cognitive load, and honors the “principle of least astonishment” that seasoned engineers live by.
2. Write clear, comprehensive documentation (and keep it updated)
Good documentation has always mattered, but “good” shifts a notch when the reader is an LLM. For an agent, docs must be complete, unambiguous, and centralized—otherwise the model treats missing or conflicting information as fact.
Start with the basics. Every endpoint needs a concise description, clearly flagged required and optional inputs, and explicit response structures including possible errors. Inline JSON examples are critical; agents rely on these to accurately infer payload structure and avoid hallucinations.
Provide an OpenAPI spec. GPT-4 plugins and many agent frameworks ingest Swagger files directly, turning specs into live API calls. A single machine-readable spec ensures your guides, references, and examples stay synchronized.
Finally, retire outdated PDFs and stale forum answers—they’ll mislead an agent just like a human. Document authentication explicitly; agents won’t guess that a 401 means “authenticate first.” Clear, consolidated, and example-rich documentation isn’t just user-friendly—it directly determines if your agent succeeds quickly or struggles through trial and error.
3. Surface errors with detail and clarity
We’ve hammered on error messages, and for good reason. Make your error messages as informative as possible without exposing security-sensitive info. Wherever feasible, include specific reasons for the error and hints to fix it. For example:
- If a required field is missing or empty, name it in the error: e.g. {"error": "Missing required field '
start_date'"}. - If a field is improperly formatted or out of range, explain the expectation: e.g. {"error": "
expiry_datemust be inYYYY-MM-DDformat"} or {"error": "quantitymust be between1and100"}. - If an ID wasn’t found: {"error": "No customer found with ID
XYZ"} instead of just "Invalid ID". - For auth issues: distinguish “
token missing” vs “token invalid” vs “insufficient scope” if you can – an agent can react differently to each.
Many teams now embed a doc link in the error body. Stytch, for instance, returns an error code plus a URL that jumps straight to the remediation page in their docs. A developer can click through; an agent, given the right tool, can fetch the page and incorporate the guidance on its next try. The message itself should remain verbose. JSON structure is fine—machines like it—but a plain-English "message" field often helps an LLM more than a perfectly terse schema. One “AI-friendly” API experiment showed that a chatty text error drove faster agent recovery than a minimal machine-formatted response.
The last step is to document every error your endpoints can throw. List the code, the conditions that trigger it, and at least one fix. Most references still gloss over error cases, yet they are exactly what an agent—or a frustrated human—needs in order to fail toward success instead of stalling out.
4. Guide users through examples and tutorials
A solid quick-start guide is a good safety harness for both humans and agents. For products involving multi-step flows—OAuth handshakes, sandbox exchanges, webhook callbacks, etc—a clear, numbered walkthrough with payload examples goes a long way. Agents can ingest these guides verbatim; a snippet from “Create your first invoice” often leads them to succeed immediately, rather than stumbling on hidden dependencies.
Providing official examples in multiple languages matters, too. Yes, an LLM can convert cURL to Python, but offering a ready-made template in Python, JavaScript, and cURL removes ambiguity around headers and JSON structure.
As you’d expect, these examples do need constant care. Nothing undermines trust like a copy-pasted snippet failing due to outdated parameters. Wire example payloads into automated tests against staging environments, so breakages surface in CI—not in front of users.
Finally, embedding live sandboxed API explorers directly in your docs demonstrates working requests in real-time. While agents don’t interact with GUIs, maintaining these interactive examples keeps your golden paths tested, ensuring everyone’s smoother experience..
5. Design for simplicity and natural use
Design choices that feel like minor conveniences for humans can be hard blockers for an AI agent. Imagine your API forces clients to list all customers, scrape the numeric ID for “Jane Doe,” then use that ID in a second call to fetch her profile.
A person can muddle through this. An agent, given only the name, has no path forward. A single search endpoint, GET /customers?query=Jane%20Doe, solves the problem for both audiences and trims two calls to one. The same principle applies to higher-level “shortcut” routes, bulk operations, or summary endpoints. If developers ask for them, then an agent will probably benefit even more because it can stay within a simpler reasoning chain.
Granularity matters, too. LLMs still have context windows; burying the one BTCUSD price somebody needs inside a 10-thousand-row payload wastes tokens and risks truncation. A filter like GET /prices?symbol=BTCUSD or a paginated response lets the model work with just the relevant slice of data and spares your bandwidth at the same time.
In short, when you streamline an API to minimize look-ups, hops, and payload bloat, you’re not only polishing DX, you’re also improving AX for agents that can’t improvise around those hurdles.
6. Close the feedback loop
Treat every agent run and every developer support ticket as data in a live feedback loop. When the same questions surface over and over again, assume your docs or API fell short; likely the agent stumbled in that exact spot. Fix the docs, add clear examples, or, if friction is structural, adjust the endpoint itself.
It’s becoming even more common now to deploy an LLM assistant within docs and Slack channels. Each time a bot answers “I'm not sure,” you've pinpointed a documentation gap. It’s search analytics on steroids. Developers get instant answers (or occasionally hallucinations), and you clearly see what's missing.
Production logs offer another view. If you see repeated calls with obsolete parameters or missing version prefixes, proactively add targeted errors (“Did you mean X?”) or gracefully handle legacy inputs. More explicit guidance helps both agents and humans self-correct.
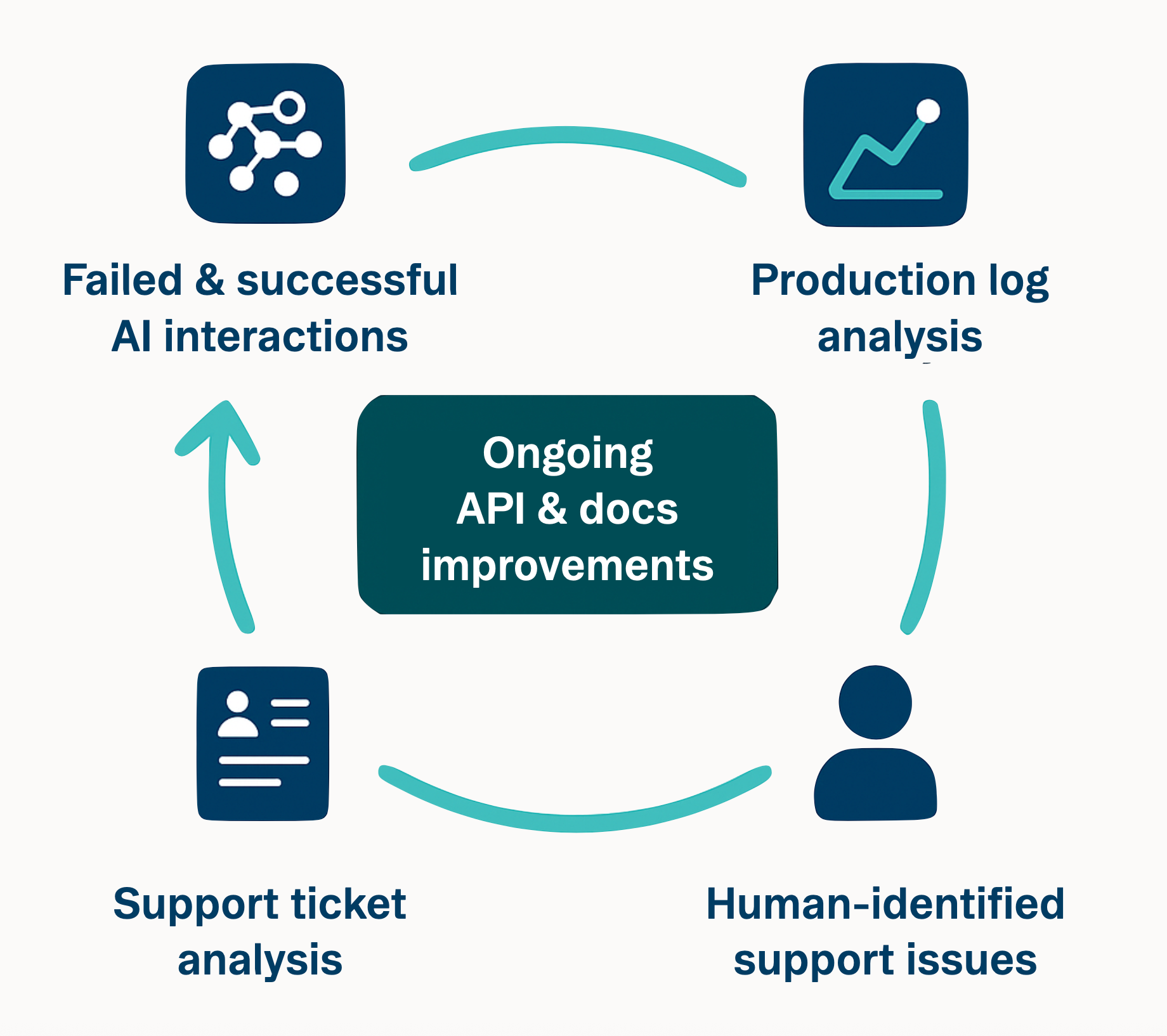
This mindset can turn DX into an ongoing practice, not a one-time deliverable. You're no longer designing just for people, but for any client—human or machine. Building for an agent's zero prior knowledge forces explicitness and consistency, creating clarity that directly benefits human developers too.
DX excellence is a win-win
LLM-powered agents are sliding into everyday engineering—writing glue code, wiring SaaS products, even answering forum posts. As that line blurs between developer and user agent, one truth holds: great DX still rules.
If an agent chokes on vague docs or cryptic errors, real developers will get stuck in the same place. Treat each agent failure as a usability bug. It flags gaps in docs, errors, or flow design that deserve an immediate fix.
This mindset merges DX and AX. The core ingredients—clear references, consistent patterns, actionable errors—haven’t changed, but the tolerance for rough edges is gone. Use an agent as a tireless intern: run the golden path, note where it breaks, patch, repeat, until the run is boringly green.
Polish the path for agents and every human newcomer benefits. Support tickets drop, word-of-mouth rises, and the next auto-code tool looking for a showcase API might pick yours. Build for the agent, and you build for everyone.
Authentication & Authorization
Fraud & Risk Prevention
© 2020-2026 Stytch. All rights reserved.