Back to blog
Generating "humanlike" code for our backend SDKs
Engineering
Jul 18, 2023
Author: Logan Gore
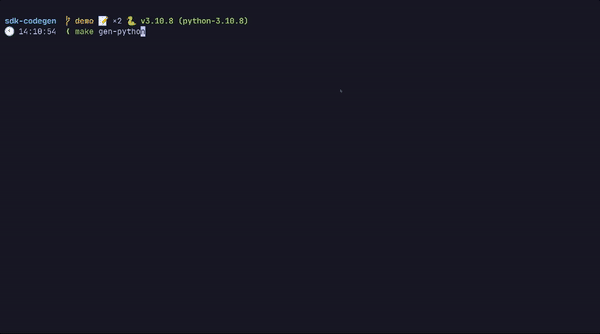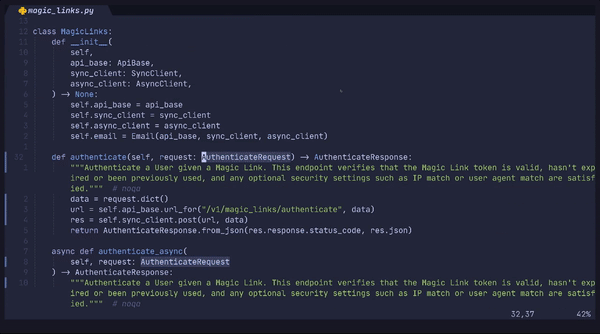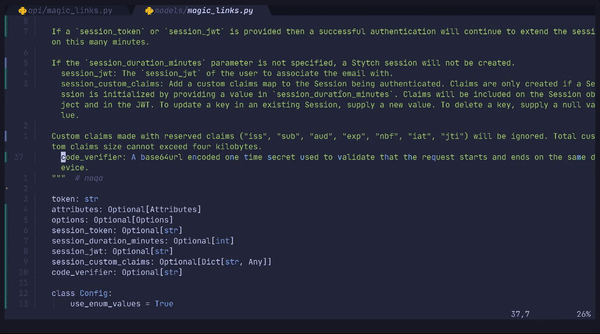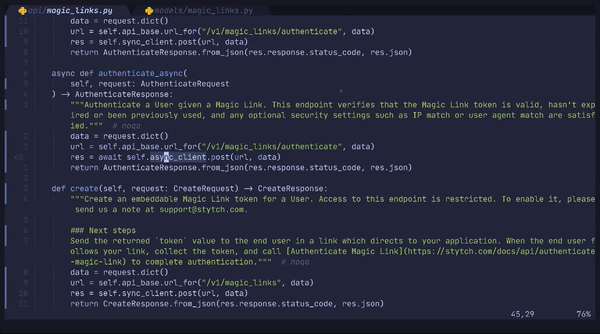
In our previous article, my colleague, aka the “intrepid lunatic” Josh walked you through some of the details of how we brought compiler theory into the authentication world by generating our backend SDK clients directly from our protobuf specs for Go, Python, Ruby, and Node.
In this article, we’ll discuss what it takes to make computer-generated code feel “humanlike” and how we generate +35k lines of code with just a few command lines at Stytch. This is essential in making sure that it’s easy for external developers to understand how our SDKs work and be able to debug their auth when something isn’t working like they might expect.
Ultimately, generating the SDKs automatically was an exercise in patience and attention to detail. Along every step of the way, we had to consider what sort of “rules” we had already implicitly adopted in our API, and how we could programmatically enforce them in our SDKs.
Let’s take a look at what made this a hard problem and how we solved it at Stytch.
Part one | What does compiler theory have to do with auth?
Part two | Generating “humanlike” code for our backend SDKs
Table of contents
Graduating from awk
Abstract Syntax Trees
Turning trees into… more trees
Turning trees into… code!
The codegen architecture
The impact for our teamTakeaways
Graduating from awk
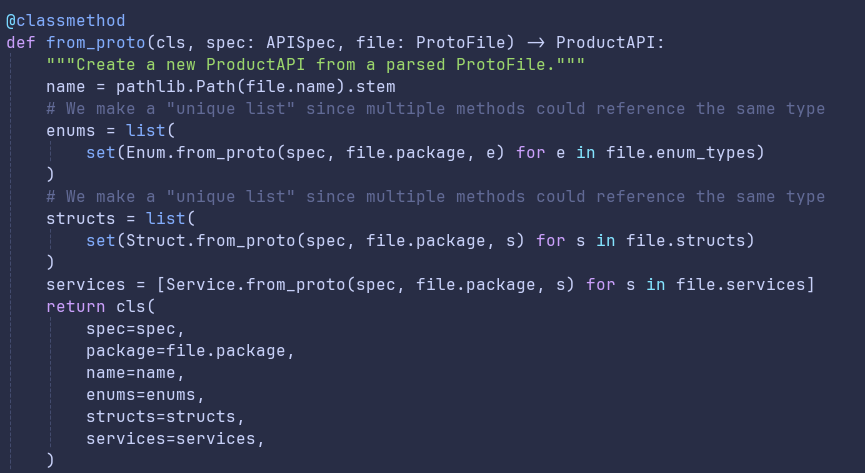
When we first wanted to try auto generating our SDKs from protobuf definitions, it began as a hackathon project. Over the course of a few days, we proved that we could parse our protobuf definitions and turn them into a spec that could be used to generate methods in our target languages.
This was a fine start, but left us with more than a few issues to resolve.
Getting protobufs into a readable format
Though our first pass was perfect for showing the viability of the approach, it was nearly impossible to debug. We had this very specifically written awk program with random bits of sed sprinkled in to make names match up – there was no logging, no debugger to jump into, and every time we found a new edge case.
In short, it was a massive pain to update.
We looked into what solutions were available for parsing protobufs already and found that buf supported outputting a protobuf spec to JSON directly. JSON is certainly a far more predictable structure than raw protobuf definitions, so we took this as our starting point to build our codegen library.
Moving to a debuggable language
The exact choice of language didn’t particularly matter for this project, but we evaluated our options through the lens of a few primary drivers:
- Our choice should be something that our developers are comfortable reading and writing.
- The language should offer strong support for logging and debugging.
- A scripting language would likely make it easier to build a solution quickly since we needed some dynamic flexibility given the recursive nature of many of our definitions.
These factors led us to choose Python to build our first version of the code generator.
Abstract Syntax Trees
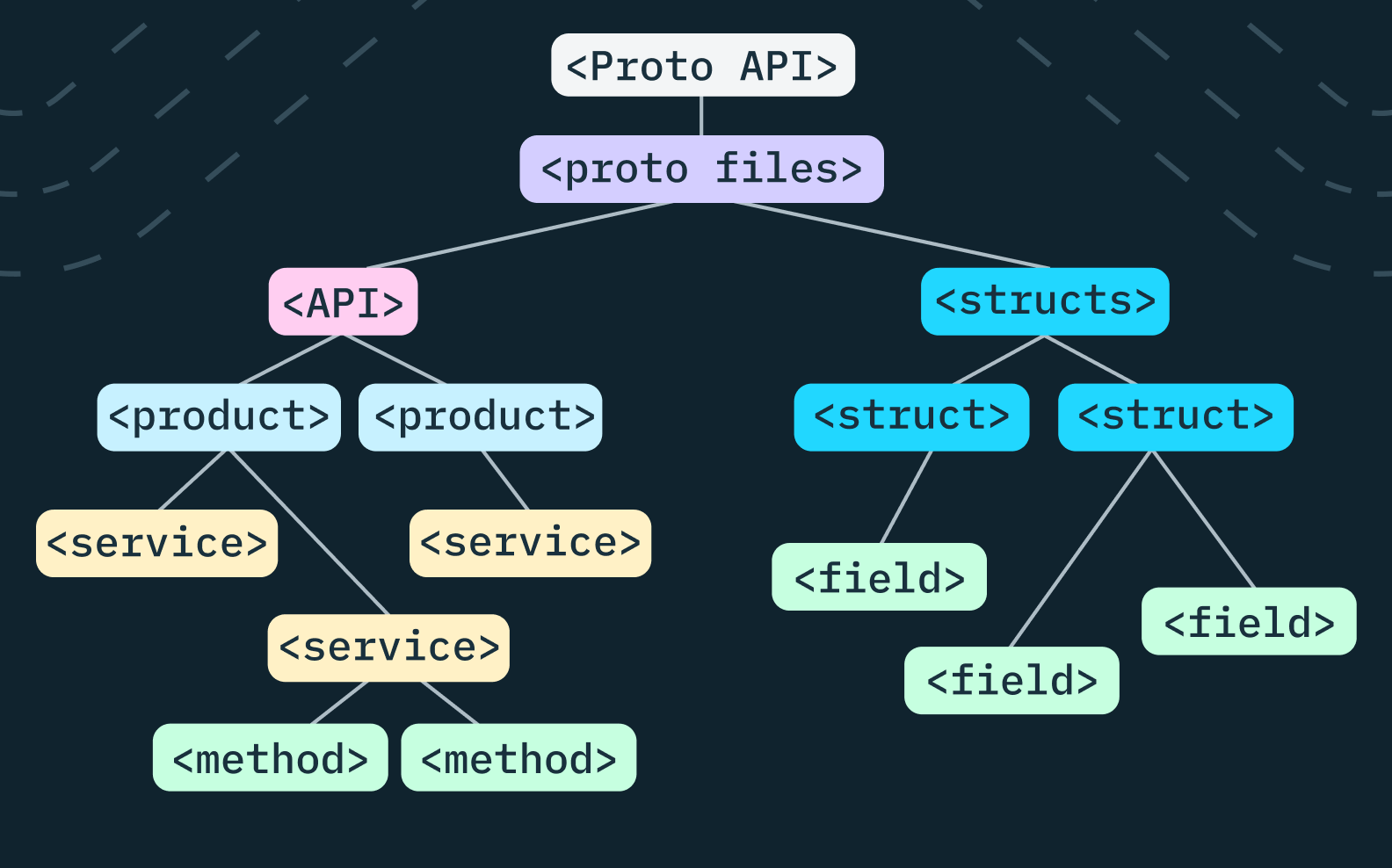
Once we had the protobufs in a JSON spec, we wanted to build an abstract syntax tree that represented the Stytch API. We didn’t think this task alone would be too difficult, but we quickly realized that our mental model didn’t necessarily match reality.
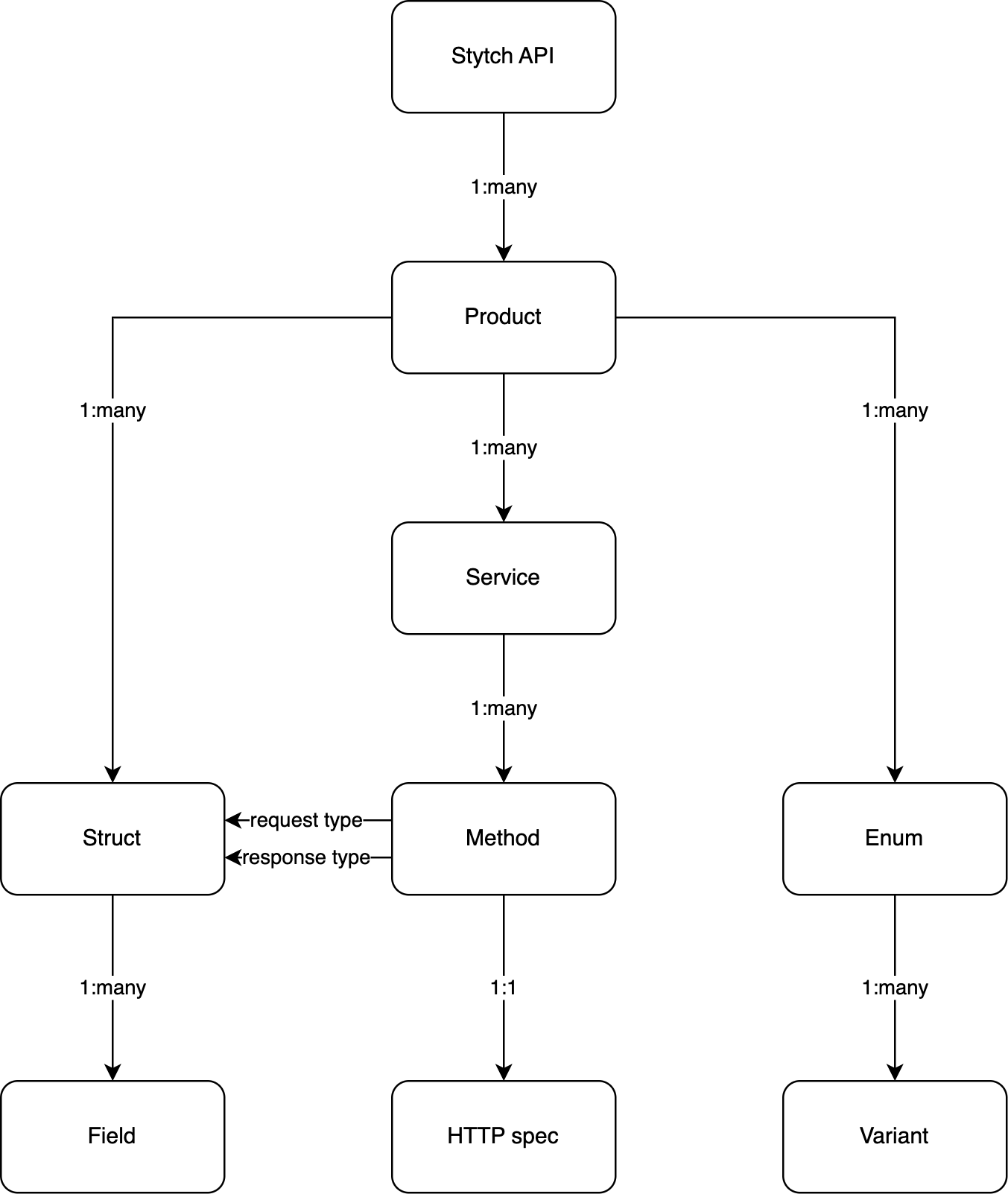
In our mental model, the Stytch API consisted of multiple products. So there would be a MagicLinks product, a Passwords product, etc. Each product could have one or more services, one or more structs, and one or more enums. Each struct had a list of fields, each enum had a list of variants, and each service had a list of methods. Each method consisted of a request type and a response type, which referenced some other struct within the product.
As we got started in development, our mental model had to be… amended.
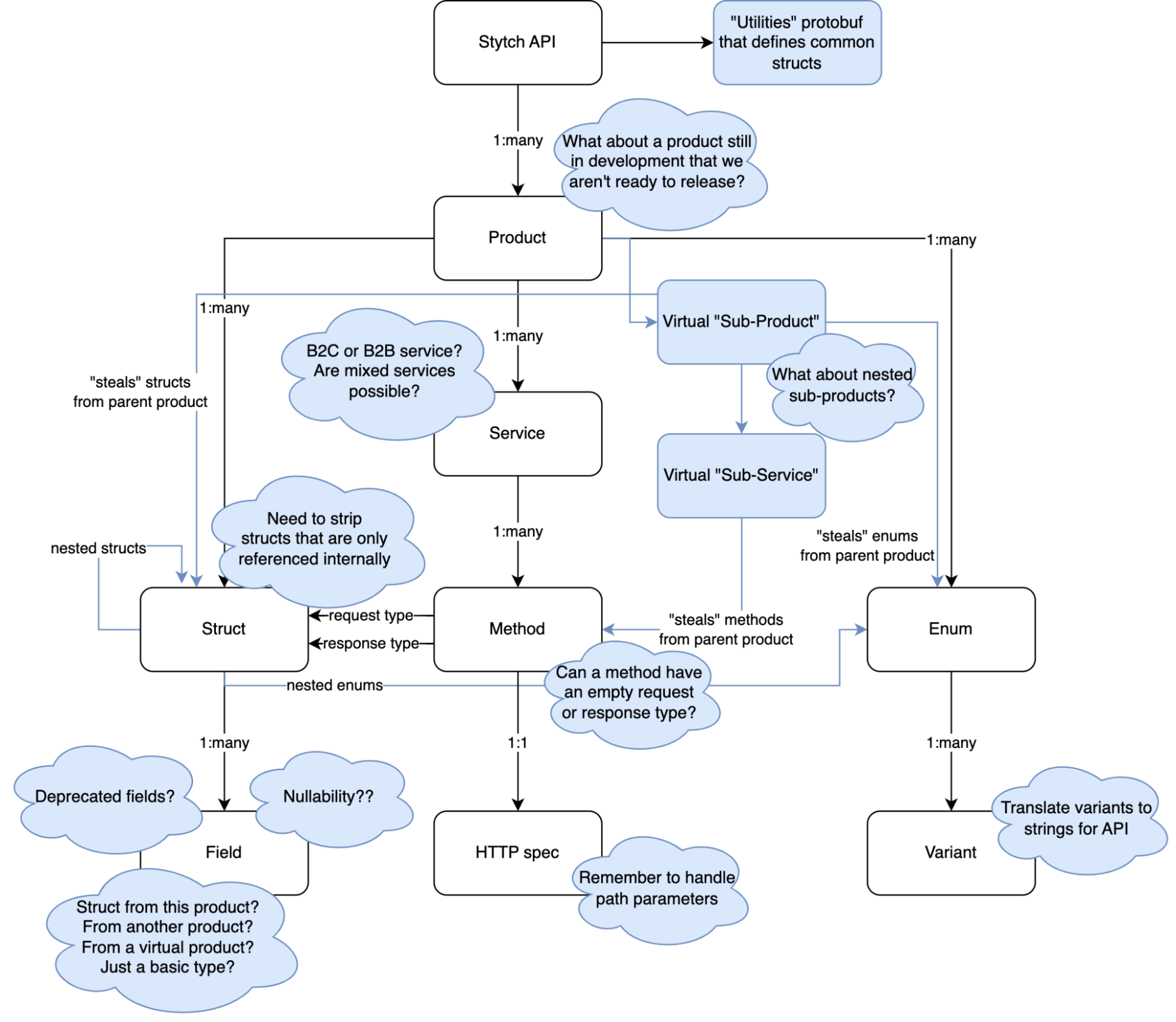
In reality, there were many edge cases to consider:
- Some protobuf files contained struct or enum definitions without actually defining any callable method. These "utility" files still needed to be generated if their structs were used elsewhere even though they wouldn't define any new services.
- Methods get added to protobufs while being developed before we're ready to expose them in our SDKs. For example, we'll be offering MFA in our B2B suite later this year, but we don't want to expose SDK stubs before it's publicly available.
- We had bifurcated our SDKs into a Consumer and B2B API and needed to programmatically parse this from the protobuf definitions. For our developers, this meant we needed to make our SDKs clear that a project had access to either the Consumer API or the B2B API.
- Our SDKs define virtual "sub-products" (like
otp.sms,otp.whatsapp, andotp.email) to make the flow more natural for developers. - In some cases, we even define nested sub-products (like
magic_links.email.discoveryin our B2B API) which means we need to allow for arbitrary nesting. - Structs which are only referenced internally but don't correspond to anything in our public SDK shouldn't be added to the backend SDKs. We have APIs like DeleteProject which can be called from the Stytch Dashboard, but aren't available as an API call from the backend SDK since programmatic deletion of your running project is a recipe for disaster.
- Fields can be nullable, fields can be deprecated, and the type of a field can be anything… a basic type, a struct, an enum, or a mapping from a string to one of those types… and those structs and enums may come from this product, another product, or a virtual sub-product.
- Many of our APIs have flexibility where there are optional parameters you may not need.
magic_links.email.send(...)allows you to attach an email to an existing Stytch user, but you don't have to do so. How could we best represent this in our SDKs to help developers understand this? - In a method's HTTP spec, a path may contain path parameters (like
/v1/users/emails/{email_id}) which need to be interpolated from the request data. - Enum variants are sent as strings from clients which get translated into proper enum types internally. We used strongly-typed enums for our API internally (like
DeliverMethod.WHATSAPP), but in an API response, we'll translate this into something more clear like"delivery_method":"whatsapp". Making this translation automatic in our SDKs would be a huge win for usability.
Turning trees into... more trees?
After turning our specs into abstract syntax trees in the "ideal" case, we started thinking about how to handle each of these edge cases. As we tackled each edge case, we had to determine how we could avoid patching immediate problems and instead solve underlying issues.
If we decided to hard code something like "the otp product has three sub-products called sms, whatsapp, and email" into our code generator, and then next month we added a new sub-product, we would have to update our code generator. This isn't impossible, but one of the biggest reasons we started this product was to free our developers' time for things other than worrying about how to build the SDKs.
The only realistic way to make codegen line up with what we had already built by hand in our SDKs was to run the generator, note what was different, and then think logically about how we could resolve the differences. This led to a three step process in our AST translation phase:
- Find an inconsistency between the generated output and existing output.
- Build an AST translation to resolve the difference.
- Ask ourselves if this was a generic translation that should apply to every SDK.
Finding inconsistencies
At each junction, we thought about how we could programmatically handle the edge case now and into the future. We examined the elements that defined the rule and codified those into our code generator. We did find some instances where we were seemingly inconsistent with our own behavior, but this allowed us to rectify those mistakes and become more internally consistent.
Translating ASTs
Taking a step back and examining what we were doing, we realized that we wanted to support a series of translators that would run on the AST and modify it according to some rule. Each language's generator would then have an abstract method returning the sequence of translators that should run on the input.
"Is this a generic translation?"
During this project, we started by trying to generate the stytch-python SDK since we had already dabbled with code generation there in the past. Every time we encountered a discrepancy between the input JSON spec and the Python code, we asked ourselves whether the transformation was something that all SDKs would need or something specific for Python. We ended up grouping all of these initial translations into something we've called the default translator.
Defining the default translator
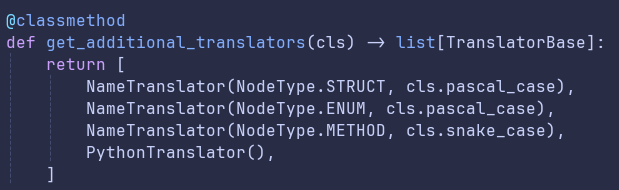
The end result is that we were able to push much of the AST translation up in the stack before we had even picked a language. This was incredibly beneficial since it meant the gap to supporting a new language gets that much shorter. Today, the Python-specific translators that get run are incredibly simple:
- We translate all method names to
snake_case - We translate all object names to
PascalCase - Types get translated to Python-specific names (
OPTIONAL_TYPE_STRINGbecomesOptional[str], for example)
Because we were able to push up so much AST generation into the "generic translator" stage, Python-specific translations are possible in under 50 lines of code. Our Go SDK is a bit more opinionated (rather… the Go language is more opinionated on variable names like userId being converted to userID), but we also have all of its translations done in under 100 lines of code.
Adding backpressure
There was a discussion about whether anyone would intentionally build a new product or endpoint that fit a rule they did not wish to cover. What if we had a new method and the default translator resulted in a "bad" translation when generating that method?
We decided that these instances would be treated as exceptions to the rule and require the Stytch developer to add the exception into the code generator. Cases where we wish to go against our own rules should be exceptionally rare, and an active decision should be made if someone wishes to be inconsistent with those rules.
Turning trees into... code!
Once the AST had been translated, we could finally start the code generation process. There are two broad categories of approaches you can take to generate code, and both have their merits and drawbacks.
Approach 1: "walk the tree"
In the first approach, you pass the root node of your AST and have your generator recursively generate the code corresponding to each node in the tree. This solution is pure in that a generator can build a render method for each type of tree node. The downside is that it can be overly abstract (no pun intended). Especially when generating an entire API, you may wish to spread definitions across different files in a repository and this can be awkward with this method.
Approach 2: templates, templates everywhere
The second approach is more recognizable to developers, even if you've never thought about code generation before: You have an object and a template… render the template. If you give it enough thought, you can easily use this solution and develop an API of arbitrary complexity just using templates. The problem here, though, is that if you don't add sufficient safeguards and suggestions, you can end up with templates spanning hundreds of lines that get difficult to maintain.
Approach 3: a hybrid model
For our case, we decided to build a hybrid approach between these two.
In our code generation, we pass the AST to the language-specific generator and let it decide how to handle it. In practice, we implement an abstract interface that defines methods for rendering a service, a method, a struct, and an enum from the AST. Generally speaking, this isn't too prescriptive and guides the codegen developer towards building something extensible and maintainable in the long term. For some languages, each service gets its own file.
For other languages, every struct may live in a centralized models file. There's no rule that perfectly fits every language, so by adopting this hybrid approach and providing tools to iterate through the AST and also define templated sections with a smorgasbord of utilities available, we've made it easy to extend our API to support new languages in the future.

Our Python generator is about 250 lines of code and 175 lines of templates. Including the translators mentioned above, we generate the entire backend Python SDK in just about 500 lines of code. This turns into 8k lines of code and inline documentation in the stytch-python repository.
The best part is that Stytch engineers no longer need to worry about updating the SDK by hand. Instead, our codegen repository will build the types and methods automatically.
Similarly, our Go generator only takes about 200 lines of code and 200 lines of templates. This means we have another entire backend SDK being written in under 500 lines of code.
For the languages we want to officially support, we can build a small “core” library that gives us the ability to easily call HTTP methods and parse JSON responses into typed structs and turn it into a fully-fledged backend SDK just by writing about 500 lines of type translations and templates. From then on, any new updates to our documentation or public API will be had “for free” in that backend SDK.
The codegen architecture
Putting it all together, we built the following architecture:
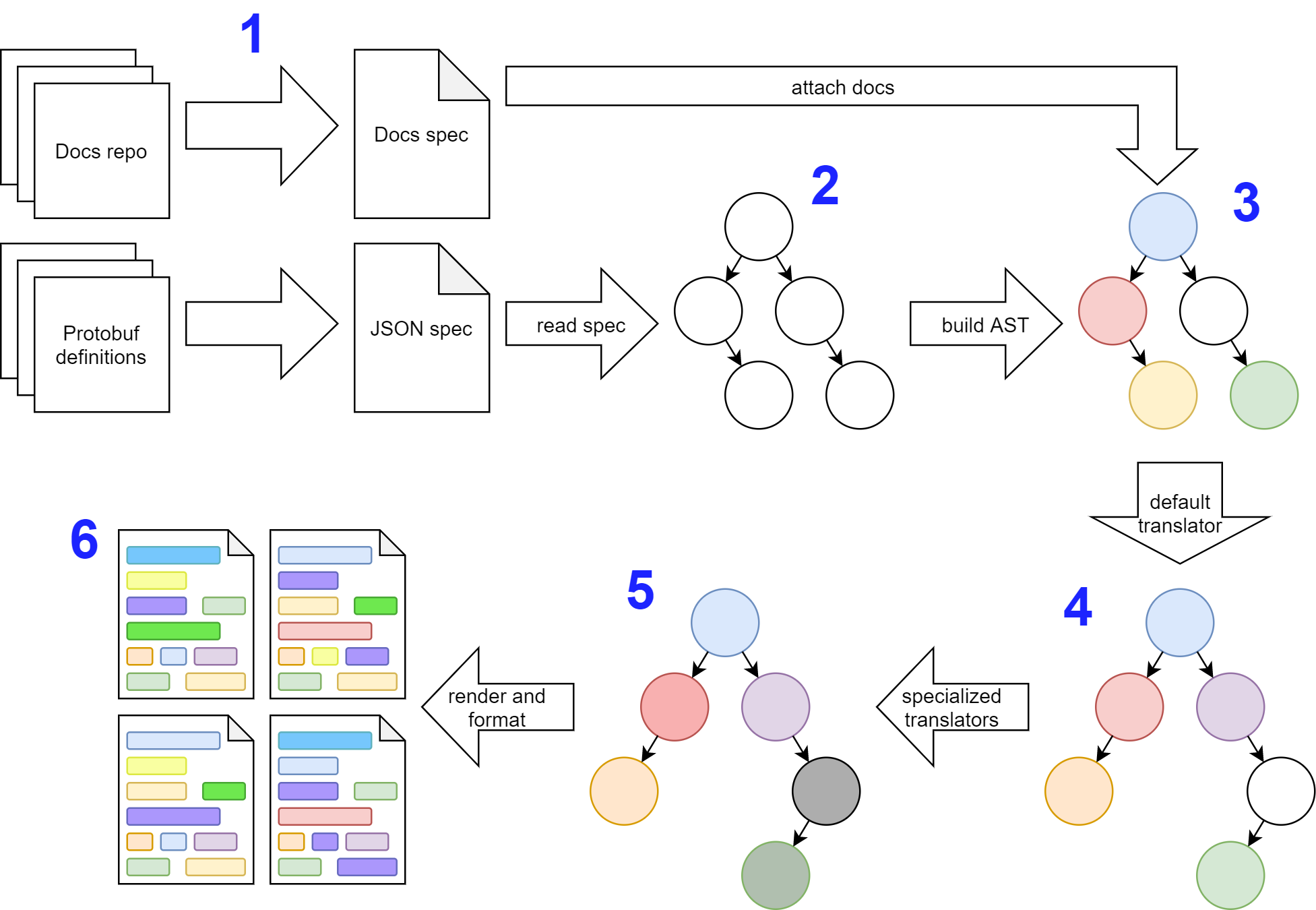
1: Generate JSON specs
In step 1, we run some commands in our docs and protobuf repos to generate JSON specs. For the protobufs, we use buf, as mentioned previously. For our docs repo, we have a simple solution that looks at exported symbols and generates a large collection of JSON objects. We'll talk about how these get joined together in step 3.
2: Read the spec into Python
We define a collection of pydantic.BaseModel objects to load the JSON spec into Python. While technically a tree at this point, there isn't much structure to it. For example, methods have declared input and output types, but these are just simple strings (like api.users.v1.User). It would be a rather tedious traversal to find the actual definition of what that User object actually is.

3: Build the initial AST
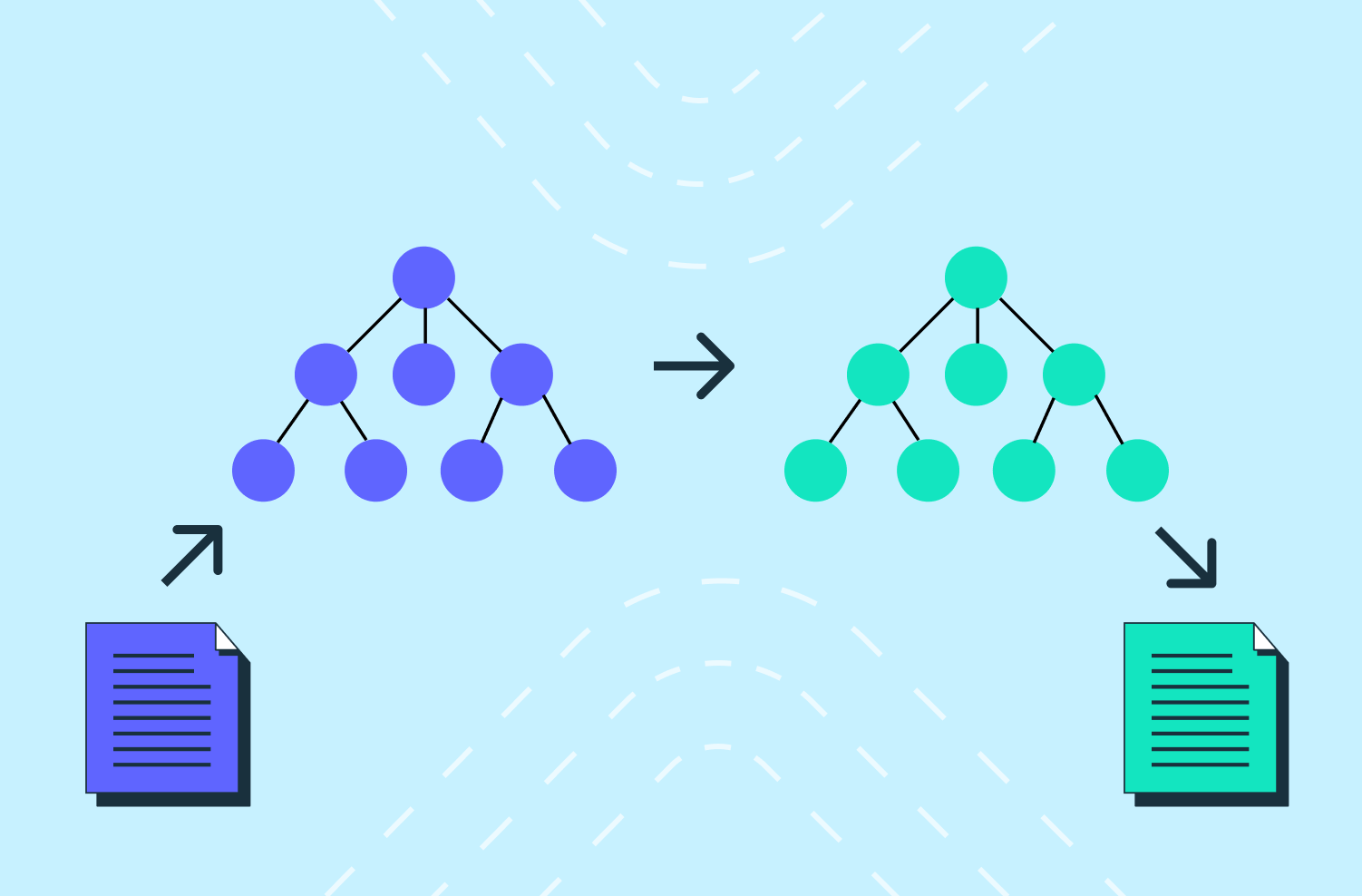
From these naïve objects, we built the "real" AST by resolving typenames to actual references to other objects in the tree. The end result is that our AST becomes something more like an "Abstract Syntax Directed Graph of Objects and References" but that doesn't really roll off the tongue as well.
The implication here is huge, though. We could now rename a struct in one place and have that propagate throughout the entire tree. So if we wanted to rename the api.users.v1.User object to something like StytchUser, every reference would also update. This gave us the power to really start molding the AST into the shape we wanted.
4: Run the default translator
We talked about the default translator earlier, but to reiterate, this is a core translator that always runs for every SDK. Philosophically, we say that the default translator fixes the AST "shape" while specialized language-based translators should only change the "color" of nodes (like renaming operations). This philosophy allows us to keep our Stytch SDKs consistent since major AST structural changes happen the same way for every SDK.
Speaking concretely, here are some operations the default translator does for us:
- Generate sub-APIs by converting methods like magic_links/email/send to MagicLinks.Email.Send(). This happens by inspecting the HTTP path of each method and determining whether it looks like it should belong to a sub-API.
- Unnest nested structs and enums and "promote" them to standalone types. Since not every language supports nested types, this promotion also helps us keep the SDKs more consistent.
- Manually rename some methods for clarity. For example, internally the getJWKS() method is just called JWKS(), but this isn't particularly descriptive to external developers.
5: Run specialized translators
Each language defines its own set of translators that get run after the default translator. Since we have made the decision that the default translator fixes structure and specialized translators just do name updates, these are basic classes. Below you can see the translators defined for our PythonGenerator.
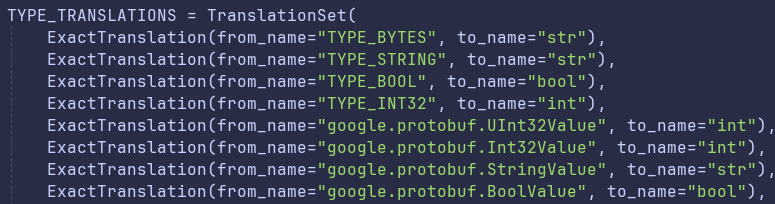
The PythonTranslator just converts protobuf type names to Python type names. In case you're curious, the special google.protobuf.XValue types below generally just refer to a nullable X, but field nullability is stored on the Field object, so we don't have to worry about translating the name to something like Optional[int] here.
6: Generate output
Once all translation is done, all that's left is to render output. We took a hybrid approach to rendering code which gave us flexibility in using the most efficient tool for the job when rendering the different kinds of nodes.
For simple nodes, we returned strings directly from methods. This worked well for nodes like Field which often rendered as a one-liner. It also allowed us to encapsulate conditional or looping logic easier, since it's generally not pretty to add conditional logic into a template file.
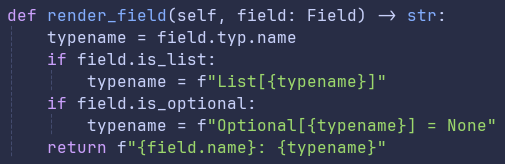
For more complex nodes, we used a templating approach that would pass the entire node into our templating engine. For a node like Method which will render as many different lines in an SDK, templates work well for making sure everything is aligned properly.
The impact for our team
At the end of June, we launched major versions of our SDKs built entirely from this codegen solution. Ultimately, this work is helping us save dozens of engineering hours from updating our backend SDKs.
For Stytch's customers, this automation ensures that all of our SDKs will be kept up-to-date and if we find a way to improve one, we can easily make that improvement in all of them (a rising tide lifts all boats). Beyond the immediate impact of freshening up these backend SDKs, this work also allows us to automate parts of our changelog by detecting when methods, fields, or even documentation gets updated.
Takeaways
- There are many reasons why our SDKs don't look exactly like our protobuf definitions (and that's a good thing!), but if we stop to consider what "rules" we've set for ourselves in those SDKs, we can internally enforce that we're consistent in the future.
- We now save dozens of hours of engineering time for Stytch developers who don't have to worry about updating every backend SDK whenever they want to release a new method or update an existing one.
- Because we were able to push up so much AST generation into the "default translator" stage, generating a new language SDK from scratch only takes about 500 lines of code (including templates).
- Looking at the bigger picture of what each of our SDKs did well let us bring those improvements to the other libraries and build a more cohesive set of backend SDKs.
We've had a lot of fun generating "humanlike" code for our backend SDKs, and we hope you enjoy using them! Check out our careers page if solving problems and reading topics like this interest you.


Authentication & Authorization
Fraud & Risk Prevention
Resources
Community
© 2020-2026 Stytch. All rights reserved.