Back to blog
Building MCP with OAuth Client ID Metadata (CIMD)
Auth & identity
Sep 29, 2025
Author: Stytch Team
One of the trickiest parts of installing a Model Context Protocol (MCP) server today isn’t the protocol itself, it’s getting clients and servers to trust each other in the first place. If you’ve ever tried to connect an MCP client to a server it’s never seen before, you’ve probably hit the registration wall.
Pre-registering with every possible authorization server doesn’t scale, and while Dynamic Client Registration (DCR) helps, its vulnerable to phishing attacks because it doesn’t provide a reliable way to verify client identity. Beyond security concerns, DCR also creates operational overhead by generating an ever-increasing number of duplicate client identities that need to be managed.
The MCP community is converging on a simpler, safer default here: OAuth Client ID Metadata documents where the client_id is an HTTPS URL pointing at a small JSON file that describes the client. The authorization server fetches it on demand, validates it, and applies its own policy, no prior coordination required. The approach is outlined in a recent blog post and an active SEP, and it builds on an IETF Internet-Draft that nails down the details.
What is CIMD?
Client ID Metadata in MCP is an OAuth method where an application’sclient_idis a secure URL pointing to a JSON file that describes the client. An MCP server fetches that file to identify the app and decide whether to trust it without requiring manual registration.
Where the current approach is struggling
MCP adopts OAuth 2.1 for authentication and client registration, but the registration story starts to break down in practice. Users typically start by picking a server. But there are far more servers than clients, and in most cases neither side has ever interacted.
DCR is a strong spec, but it’s not a great fit for this particular model. It leads to an unbounded stream of writes to /register. Each client instance gets its own ID, which creates a flood of per-instance identifiers.

Operators then have to juggle expiry rules, handle storage, and defend against abuse on the open endpoint. It works, but it creates significant operational overhead for what should be a lightweight connection.
The idea behind Client ID Metadata
The IETF draft introduces a simple concept: instead of using a random string as the client_id, the client’s identifier is an HTTPS URL. That URL must include a path, and when an authorization server encounters it, the server fetches a JSON document from that location. Inside the document, the client_id property must exactly match the URL itself, ensuring the identifier and metadata are bound.
The document contains a human-readable name, a list of redirect URIs, and the client’s authentication method. Servers can then cache the document according to standard HTTP rules with their own cap on how long to keep it. To signal they support this flow, servers advertise a simple flag in their discovery metadata.
As an example, Bluesky already started using this model in production. In their system, the client metadata must be hosted at a URL that doubles as the client_id. If you’ve integrated with their OAuth profile, you’ve already worked with Client ID Metadata.
What building with Client ID Metadata looks like
Clients see very little change from their point of view. The authorization request still looks familiar. You’re sending PKCE parameters, scopes, and state, except now the client_id isn’t a random string. It’s the URL of your metadata file.
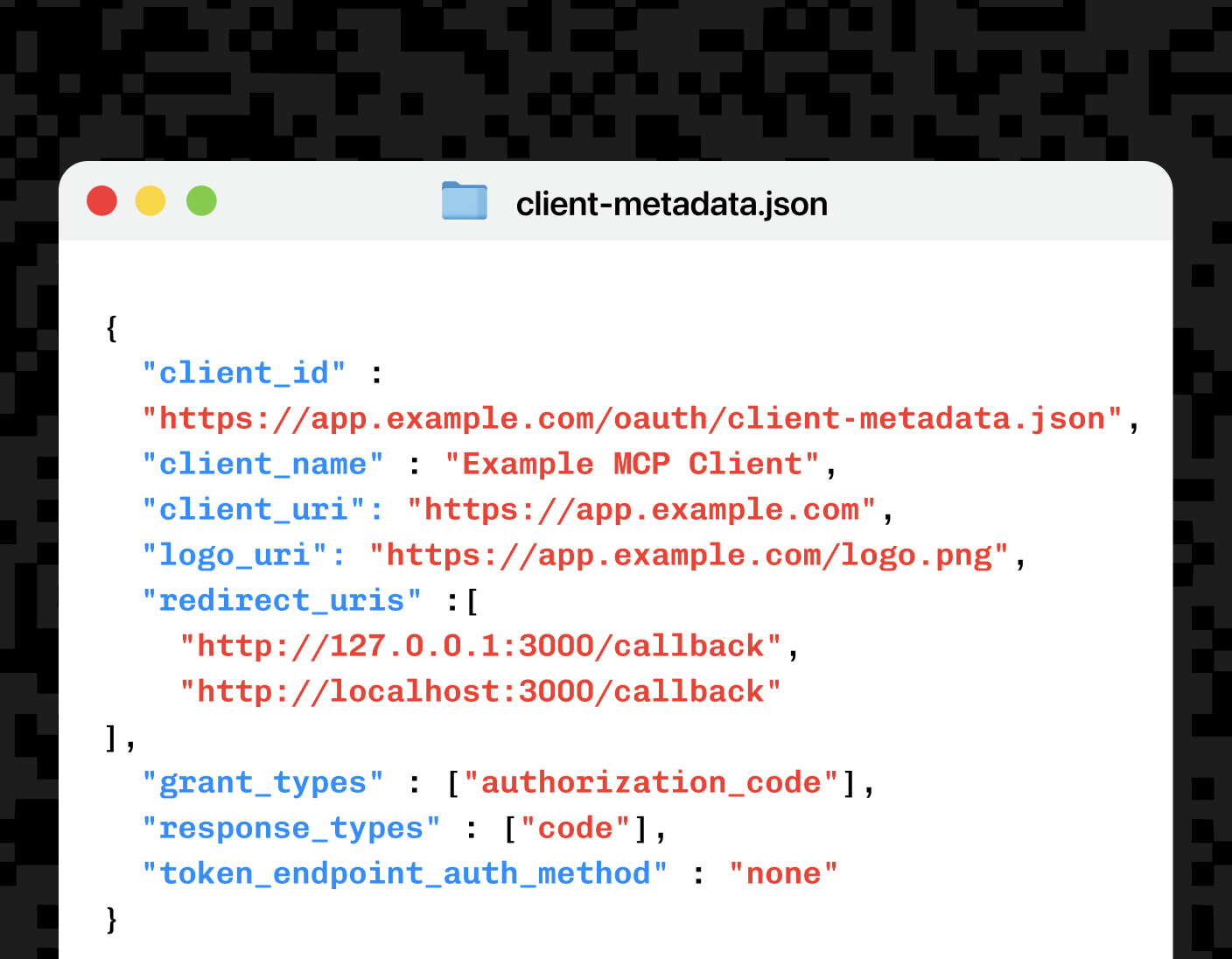
That file is just JSON, hosted at a stable HTTPS URL. A minimal example looks like this:
{
"client_id": "https://app.example.com/oauth/client-metadata.json",
"client_name": "Example MCP Client",
"client_uri": "https://app.example.com",
"logo_uri": "https://app.example.com/logo.png",
"redirect_uris": [
"http://127.0.0.1:3000/callback",
"http://localhost:3000/callback"
],
"grant_types": ["authorization_code"],
"response_types": ["code"],
"token_endpoint_auth_method": "none"
}This covers the basics: a client_id that exactly matches the document URL, a human-readable name, an explicit allow-list of redirect URIs, and an authentication method. Public or native clients typically use "none", while confidential clients can advertise private_key_jwt and publish a JWKS for validation.
On the server side, the first encounter with a new client follows a predictable pattern. The server fetches the metadata document over HTTPS, enforcing strict limits on size, timeouts, and which networks it will talk to (learn more about protecting against SSRF attacks). It then checks a few invariants: the JSON’s client_id must equal the URL, the redirect_uri in the request must appear in the list provided, and the document must be well-formed. Once validated, the server can cache the result — usually for up to 24 hours — so it doesn’t need to refetch on every login. With that in place, it renders a consent screen using the client’s name and continues the standard OAuth flow.
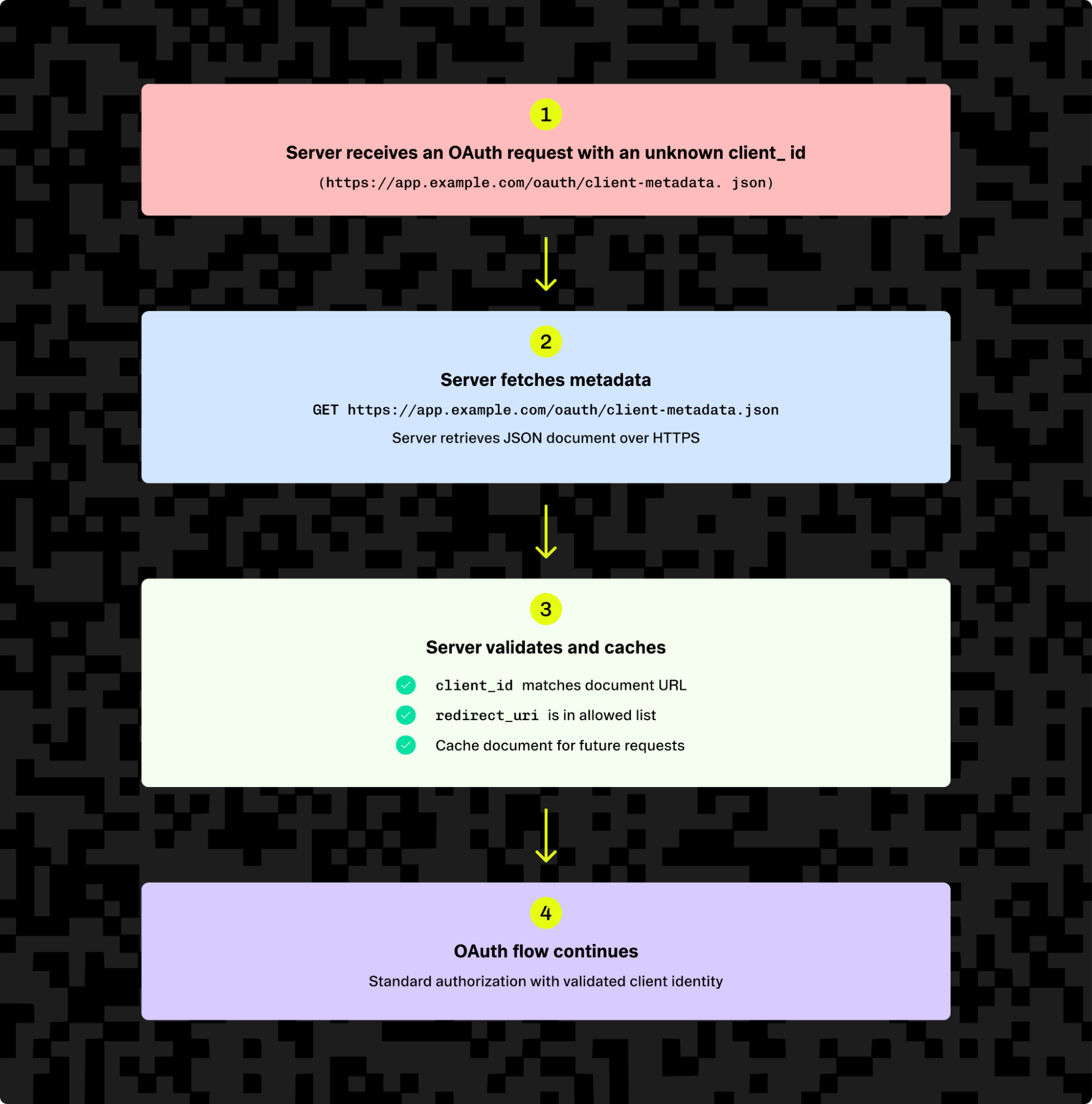
That’s the whole point: no /register endpoint, no database of per-instance IDs, just a natural “one URL per app” model. Operators get a stable identifier they can reason about, and clients get to connect without extra coordination.
Why this fits MCP’s shape of the world
MCP’s value is that any capable client can talk to any conforming server. That’s exactly the kind of environment where URL-based Client ID Metadata makes sense.
Here’s why it fits so well:
- Trust without pre-coordination. Servers don’t need a standing registration database or prior agreements. They can accept all clients, restrict to trusted domains, or allow just a handful of specific URLs — whatever matches their own risk posture. The SEP frames this as server‑controlled trust rather than client‑led registration.
- Stable identifiers. Because the
client_idis a URL, it represents the app itself rather than an individual installation. That reduces churn from per-instance IDs and gives operators a clearer, more durable identity to work with. - Redirect URI attestation.
redirect_urisare explicitly bound to the client in its metadata document. This makes it far harder for attackers to sneak in malicious callbacks since the server enforces the list from the JSON file. - Low implementation cost. Hosting a static JSON file is trivial for most apps. Even desktop clients typically have a website where they publish downloads — and that same site can serve the metadata document with almost no extra effort.
So in short, Client ID Metadata removes a lot of the overhead from registration while also giving servers clearer, more trustworthy signals about who a client really is. For a comprehensive guide to MCP authentication patterns, see our MCP authentication and authorization implementation guide.
What it doesn’t magically solve (and what to do instead)
Even though Client ID Metadata makes registration much simpler, there are still a couple of gaps it can’t fully close. But it’s worth noting that these risks aren’t new, and you’d hit the same ones with DCR.
Localhost impersonation
If your client uses http://localhost redirect URIs, an attacker running on the same machine could pretend to be your app. They’d reuse your metadata URL and bind to the same local port, intercepting the authorization code when the user approves the request.
This vulnerability is a fairly well-known OAuth limitation, not something Client ID Metadata introduces, but the open nature of MCP makes it more visible. To address this, servers should always request explicit user consent when approving localhost-only clients. Developers can also raise the bar with software statements or short-lived JWTs signed by a client-owned back end. These add friction for attackers, even if they don’t eliminate the risk entirely.
Fetching untrusted URLs
The other challenge is that authorization servers are now fetching URLs provided by unknown clients. That creates the possibility of server-side request forgery (SSRF) or abuse through large responses and slow connections.
The best defense here is to harden the fetcher. Block internal and loopback IP ranges so the server can’t be tricked into calling sensitive endpoints. Set strict size limits and keep the metadata file to just a few kilobytes. You can also use aggressive timeouts and rate limiting to avoid being tied up by slow responses or floods of requests. Finally, you can cache valid documents so you don’t have to re-fetch them on every login.
Where the spec is heading
The current proposal is to make Client ID Metadata the default for new MCP deployments. In spec terms, that means treating it as a SHOULD for servers, while leaving Dynamic Client Registration as a MAY and pre-registration available where direct relationships exist.
This approach gives the ecosystem room to evolve. Servers can adopt OAuth Client ID Metadata incrementally without breaking existing clients, while developers relying on DCR or pre-registration don’t need to change anything right away. Over time, URL-based client IDs are expected to become the normal, lightweight way to connect new apps. Learn more about how to create and host CIMD for your OAuth applications here.
It’s important to note that this shift is about simplifying operations, not solving every identity challenge. Stronger attestations or platform-level guarantees (like device checks or signed software statements) remain open questions. Those can be layered on later, while Client ID Metadata handles the day-to-day registration pain.
The path forward is clear: make registration lighter while leaving space for stronger identity signals as the ecosystem matures. Products like Stytch Connected Apps are already adapting to this change, making it easier to work with Client ID Metadata now while staying compatible with existing OAuth deployments.
Want to start building with CIMD today? Head over to the Stytch docs on CIMD to get started.
Authentication & Authorization
Fraud & Risk Prevention
© 2020-2026 Stytch. All rights reserved.