Back to blog
Optimizing DBs at scale: how we reduced writes by 1000x for one of our most accessed tables
Engineering
Dec 21, 2023
Author: Logan Gore

Most of us have probably heard the quote, “Premature optimization is the root of all evil.” At some point, though, you may come to realize that there is a serious bottleneck in your system and it’s no longer premature – you need to optimize to meet the scale you’re now facing.
When writing an application, you may have encountered the guideline that you should let your database just handle the things it does well and not try to get too clever or creative with your queries. In the majority of cases, the engineering hours lost from someone having to debug something “clever” will outweigh the benefits of you saving a few milliseconds in every API call.
But what do you do when you start to hit a limit? You reach a point where there’s a noticeable impact on your database and it threatens to block you from scaling further. Now it’s not premature – now it’s just optimization.
Today we’ll talk about how we reduced writes by 1000x for one of our most accessed tables, saving us valuable DB CPU and freeing up dozens of connections to do more impactful work.
Sessions custom claims
Sessions are by far the biggest product at Stytch in terms of number of API calls – and that makes sense. No matter which authentication factors you support in your application, chances are that you’ll also choose to use Stytch Sessions to reap the benefits there.
One common operation is to add custom claims to a session. This is arbitrary JSON data you can assign to a user session. This could be something like a URL to a profile picture for the user, their preferred display name, or any other data that could be useful to your application.
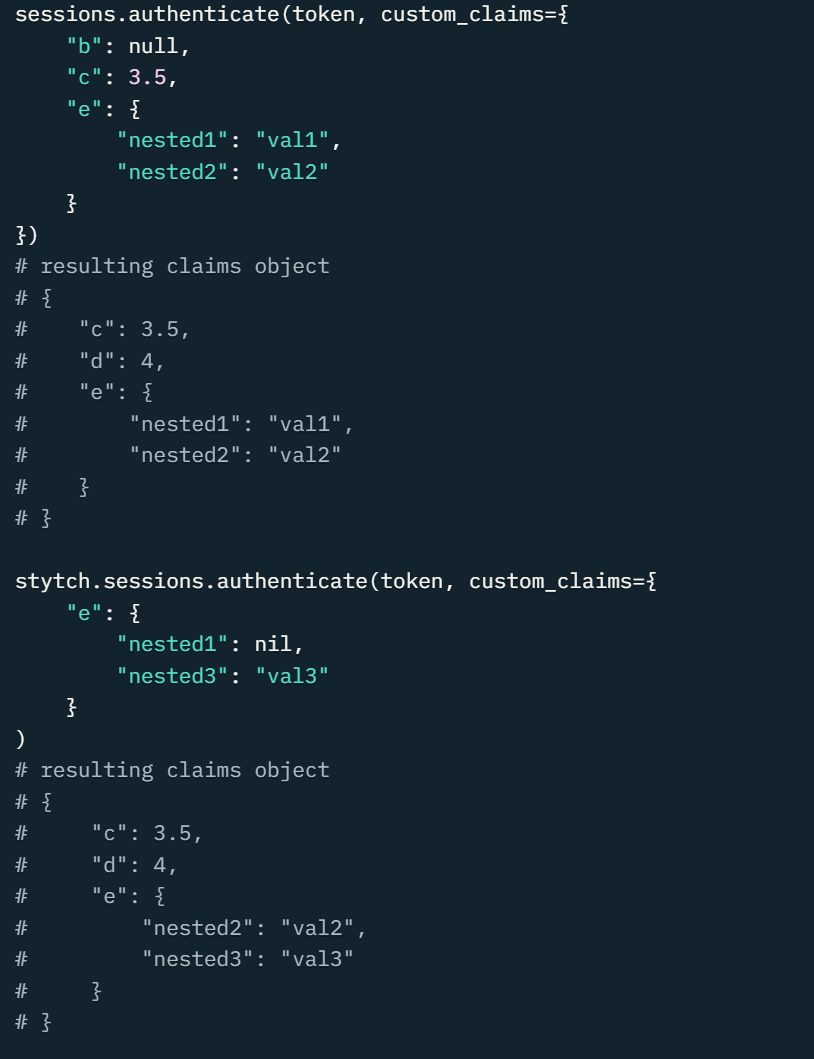
Most projects will make use of custom claims for something, but it’s a relatively rare occurrence for this data to actually change.
By optimizing one of the hottest functions in our codebase, we were able to shave a significant number of writes from our database by being smarter about how and when we choose to perform an update. This ultimately allowed us to drastically cut back on the number of concurrent open connections to our production database.
No-ops are free, right?
Custom claims are read every time a call to SessionsAuthenticate is made to Stytch. Additionally, every other /v1/:product/authenticate call has a chance to read custom claims if the authentication is linked to an existing session. As for writing custom claims, if the incoming request included any custom claims at all, we upsert those claims back into the database.
If you look at any random authentication call, you would see that only a tiny fraction of the total time is spent handling custom claims (generally around 1-3ms) and doing this upsert.
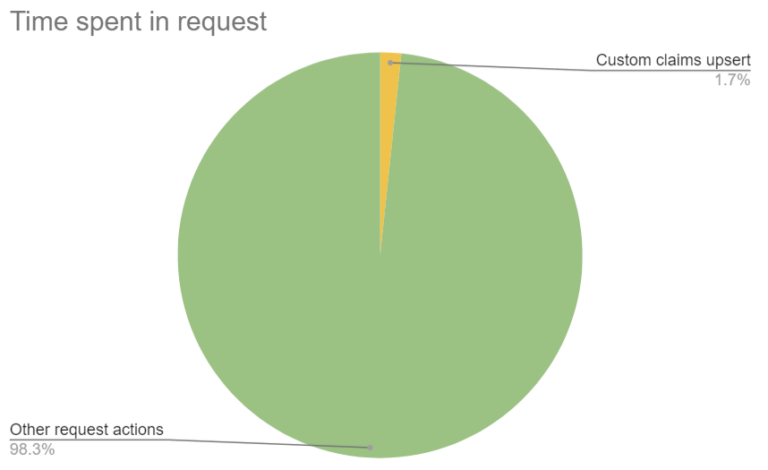
On average about 1.7% of the time spent in a request involves an upsert into the custom claims table.
But while the time spent in a single request is inconsequential, take a step back and you’d realize that aggregated over all calls, a significant number of db connections were used in this code path. In fact, about 4% of all database queries were going through this no-op flow.
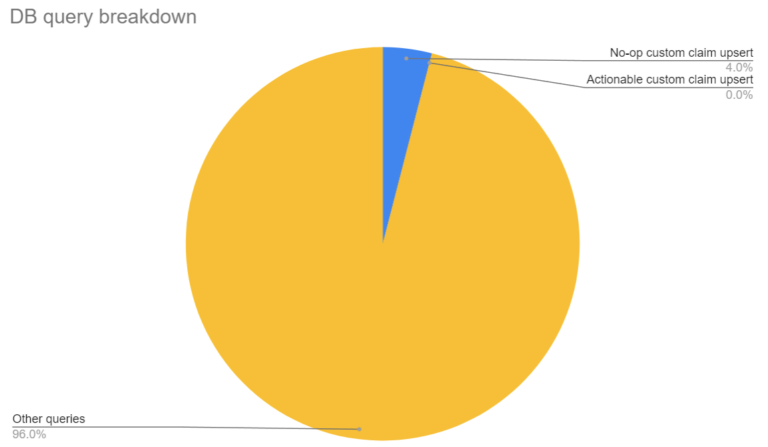
No-op custom claim upserts used to account for 4% of all db queries while actionable custom claim upserts made up just 0.01% of queries.
Quick note: the actionable upserts are closer to 0.01%, but rounding makes it look like they’re not even present!
The vast majority of the time, custom claims aren’t changing. Even if they’re being sent in every request from an application, those applications typically just send the same custom claims we’ve already stored in our database. The end result? We’re calling a no-op update… often.
We knew that this was a no-op, but we didn’t care. Our upsert operation accounted for this possibility and we thought it was reasonable to leave the logic to MySQL. This allowed us to simplify the application code and avoid maintaining too many different paths for control flow.
While there’s no harm in doing these no-op updates, as we began scaling, we realized that we were taking over a database connection that could be used for something more useful. And at times where our system experienced a spike in requests, we saw a noticeable increase in internal errors due to requests being blocked waiting for a database connection.
Getting smarter: detecting updates
As exponential growth drove us to optimize performance where possible, we reached a point where we wanted to start being more cognizant of how often we were talking to the DB in our Sessions product.
When we perform a SessionsAuthenticate call, we know what we’ve previously stored in the database and we know what we’ve been sent in the request. So then, there’s a solution: if those two claims are equivalent, we know we can skip the upsert!
In our Go codebase, that could be modeled with a function like so:
func DoClaimsMatch (
dbClaims map[string]any,
requestClaims map[string]any,
) boolWe can go one small step further, though. We’re not just checking whether the two sets of claims are equivalent – we want to know if we have any claims to add, modify, or delete from what we’ve stored in the database. We already had a function for merging claims together…
func MergeClaims (
dbClaims map[string]any,
requestClaims map[string]any,
) map[string]anySo we just had to modify it slightly to also return whether any update occurred.
func MergeClaims (
dbClaims map[string]any,
requestClaims map[string]any,
) (merged map[string]any, didUpdate bool)Later in our code, we added a simple condition that if didUpdate is false, we don’t even ask the database to perform the upsert – we know it will be a no-op. This saved us a call to the database and freed up a connection to do something more useful.
The results
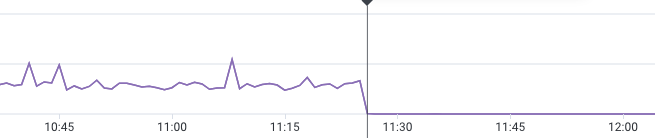
When we switched over to the new logic to skip no-op upserts, we saw a 99.9% reduction in custom claim writes
The results were instantaneous. Writes to custom claims dropped off so significantly, the graph would make you think they stopped completely. We’re still writing and updating custom claims – but only 0.1% of requests actually trigger a DB write now, which is a massive win for us.
There was a ripple effect in our database when we deployed this change. We saw a small reduction in DB CPU, we reduced our average number of open connections, and we saw a modest improvement in our p75 and p99 response time metrics (due to requests not getting stuck waiting for a DB connection).
What we learned
We don’t regret how our system was initially designed. While it wasn’t overly complex to add the logic to skip the no-op write, it was certainly more complex than doing nothing and letting the database handle it completely. Adapting to current needs is a key problem in navigating the complexity of system scalability.
The introduction of nuanced logic to skip the no-op writes in custom claims showed us the balance we must strike between code simplicity and strategic optimization. We were able to use this opportunity to shine a light on other slow or frequent queries and decide which ones need addressed as we continue to scale.
From this experience, we’ve started to build more tooling and dashboards to allow us to step back and view system performance more holistically. Over time, this should help us to understand our bottlenecks long before they ever pose a real threat to Stytch’s ability to scale.
Check out our careers page if solving problems and reading topics like this interest you!


Authentication & Authorization
Fraud & Risk Prevention
Resources
Community
© 2020-2026 Stytch. All rights reserved.