Back to blog
What are webhooks?
Auth & identity
May 22, 2024
Author: Isaac Ejeh
Webhooks are a simple but efficient way for applications to communicate with each other in real-time, without having to make multiple API calls. Whenever an independent system needs to make decisions or trigger certain internal actions based on disparate events in another system, it can create a unique URL where it receives payloads in either JSON or XML format.
In this article, we’ll explore webhook architectures and their real-world use cases, discuss best practices and potential security considerations, and demonstrate how you can use webhooks to build efficient, event-driven systems.
How do webhook architectures work?
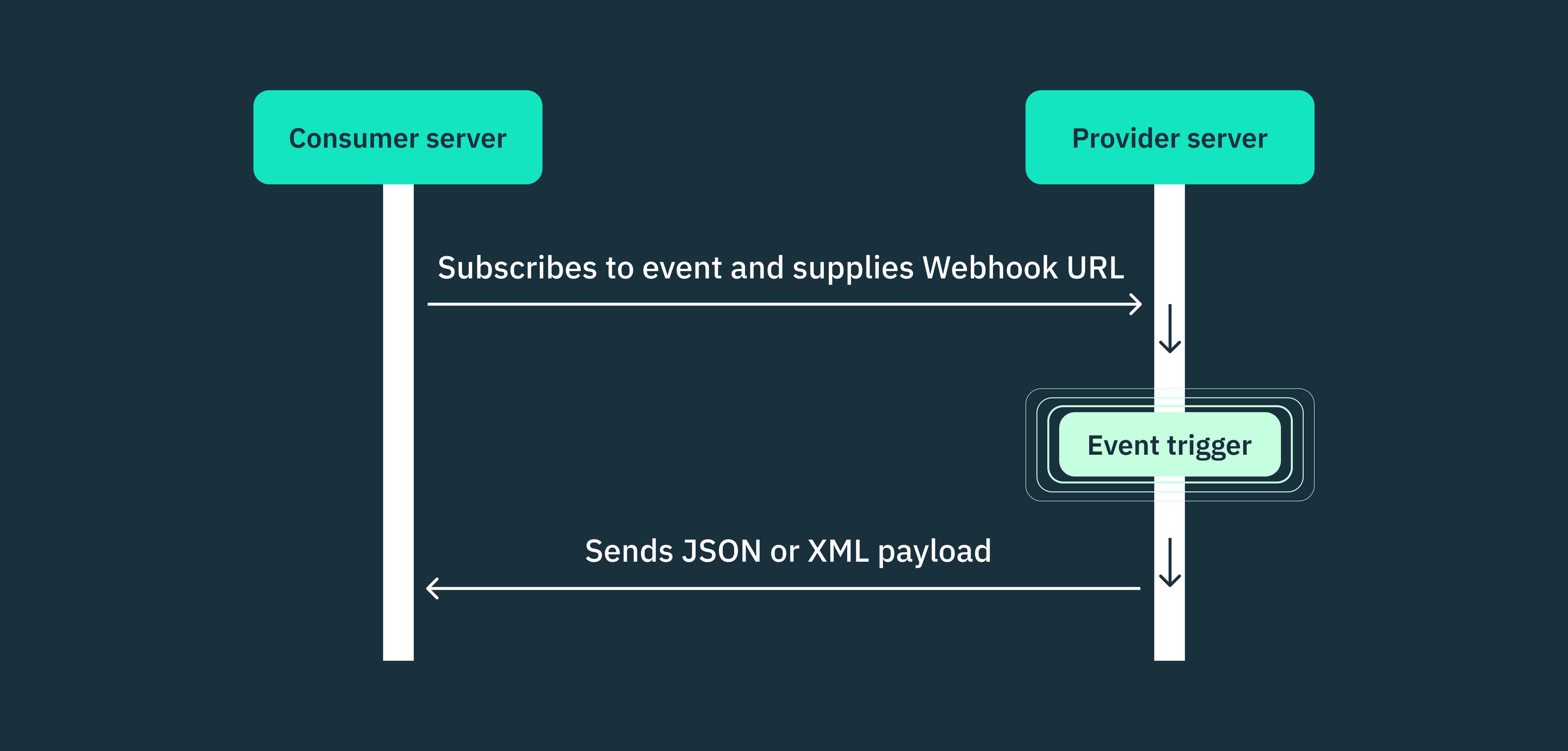
All webhook architectures typically have two primary components: the webhook provider and the webhook consumer.
A webhook provider could be an application, platform, or service that exposes an interface for other systems to subscribe to specific events and receive real-time updates. It’s solely responsible for generating and sending webhook notifications to the consumer.
On the other hand, a webhook consumer is the system that receives and processes webhook notifications from the provider. It could be an application, function, microservice, or any other system capable of handling incoming HTTP requests.
Webhook subscription
To establish a webhook connection, the consumer application must first subscribe to the desired events offered by the provider. This process typically involves the following steps:
- The consumer application registers a unique URL (webhook endpoint) with the provider, specifying where it wants to receive the event payloads.
- The provider stores the webhook endpoint URL and associates it with the selected events.
- Whenever a subscribed event is triggered, the provider sends an HTTP request containing the event data to the registered webhook endpoint.
Webhook request methods
Webhook requests can be sent using various HTTP methods, but POST and GET are the most commonly used request methods.
In POST requests, the event payload is contained in the request body and may include additional information, such as authentication tokens in the header. POST requests are not idempotent, so sending the same request multiple times may result in duplicate data or actions.
In GET requests, the event payload is included as query parameters appended to the webhook URL. These requests are idempotent, meaning that sending multiple identical GET requests will produce the same result without side effects. It’s important to note that GET requests are mostly used to verify if a webhook endpoint exists.
While POST is the most widely used method for webhooks, other HTTP methods like PUT, PATCH, and DELETE may be employed in specific scenarios, such as modifying or deleting data.
Webhook POST requests follow the typical HTTP request structure with a start line, header, and payload.
POST /webhook HTTP/1.1
Host: consumer.example.com
Content-Type: application/json
X-Webhook-Signature: sha256=abcdef1234567890
{
"event": "user.created",
"data": {
"id": "1234",
"name": "John Doe",
"email": "john.doe@example.com"
},
"timestamp": "2023-04-25T10:30:00Z"
}
HTTP/1.1 200 OK
Content-Type: text/plain
Webhook received successfullyWhen would I use this in the real world?
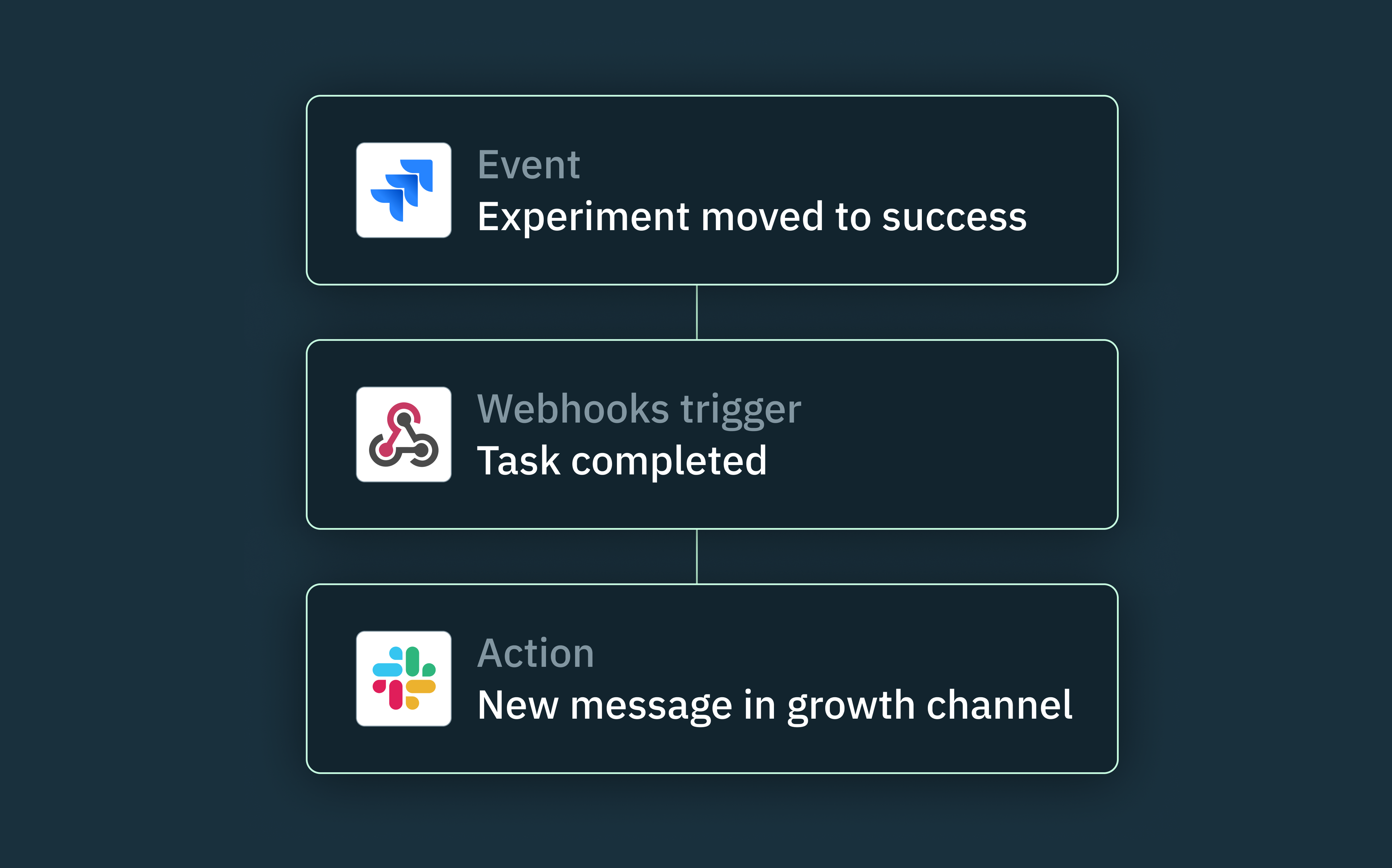
To think about how this might work in a real-world example, let’s imagine your engineering team uses a version control system like GitHub and would like to receive notifications in Slack when certain events, such as pull requests or commits, occur on GitHub. Slack, which is the consumer application, would have to provide a webhook URL where GitHub can send real-time notifications whenever any of the specified GitHub events take place. Instead of Slack having to continuously poll GitHub for new events, it’s much more efficient for GitHub to send a notification to Slack only when a relevant event occurs.
Whenever a Slack admin successfully installs the GitHub app via an OAuth verification code exchange, Slack automatically sends an OAuth response to GitHub. This response typically includes an “incoming_webhook” object containing a pre-generated “URL” field where the GitHub app can post data in real-time.
In this way, whenever a subscribed event triggers in the connected GitHub repository, GitHub will send a POST request containing the event details to Slack’s webhook URL. Slack then parses the requested data, formats it into a message, and sends it to the specified Slack channel, ensuring users stay up-to-date with the latest activity in their GitHub repositories.
If roles were reversed and we wanted to perform certain actions on GitHub right from Slack without having to visit GitHub directly, the implementation would follow a similar process. However, in this case, GitHub has to provide a webhook URL for Slack to send data to.
Webhook responses and error handling
When a webhook consumer receives a request, it typically acknowledges receipt by sending an appropriate HTTP status code (e.g., 200 OK) and may optionally include a response body. If the consumer encounters an error while processing the webhook, it usually responds with an error status code (e.g., 400 Bad Request) and provides details about the error in the response body.
Webhook providers also implement retry mechanisms to handle these kinds of cases where the consumer application is unavailable or fails to process the webhook. This ensures that no events are lost due to temporary issues and maintains the reliability of the integration.
Examples and use cases of webhooks
Beyond the basic GitHub/Slack notification example described above, webhooks can be incredibly useful in other software development settings. Let’s look at a couple here.
Enterprise user provisioning via SCIM
To centrally manage employee identity and access permissions across internal systems and external applications, most enterprise companies rely on the SCIM protocol, or System for Cross-domain Identity Management. SCIM is an HTTP-based protocol that leverages REST APIs to facilitate onboarding new users, setting their permissions, managing role changes, and offboarding users across multiple domains.
In a typical SCIM setup, the company’s IAM system or identity provider (SCIM IdP) such as Okta or Microsoft Entra ID acts as the “client” and is responsible for storing and managing the identities and permissions required by service providers. The SaaS applications employees use for work within the company (i.e., Slack, GitHub) are known as “service providers.”
Whenever an administrator makes CRUD changes to a user account on the IdP, SCIM automatically propagates these changes to all connected service providers, ensuring that all systems remain in sync without admins having to manually effect the same changes across every SaaS app.
However, for enterprise applications and their connected service providers to receive this kind of automatic updates from their IdP via SCIM, they need to provide a SCIM connector base URL which will act as a SCIM endpoint.
The options they have are either to build a native SCIM connector within their application, which can be complex and time-consuming, or leverage auth platforms like Stytch. By leveraging the SCIM base URL provided by these auth providers, enterprise apps can easily configure their IdP to send updates without the need for a custom SCIM implementation.
// Example SCIM connection object via Stytch
{
"connection": {
"organization_id": "organization-test-07971b06-ac8b-4cdb-9c15-63b17e653931",
"connection_id": "scim-connection-test-cdd5415a-c470-42be-8369-5c90cf7762dc",
"status": "active",
"display_name": "My SCIM Connection",
"idp": "okta",
"base_url": "https://test.stytch.com/v1/b2b/scim/scim-connection-test-cdd5415a-c470-42be-8369-5c90cf7762dc",
"bearer_token": "9LmcAfUxGGMSNzfROGY762wTD3A6DQsD3hmxbrAJaEjTsdko",
"bearer_token_last_four": "sdko",
"bearer_token_expires_at": "2029-03-20T21:28:28Z",
"next_bearer_token": "8TqbGcJyFFLSNveQPGZ861xSE2B7CPtC2gnyasAIbDiUrcjn",
"next_bearer_token_expires_at": "2030-03-20T21:28:28Z"
}
}
// Example update member SCIM event (scim.member.update) via Stytch
{
"project_id": "project-live-123-...",
"event_id": "event-live-456-...",
"action": "UPDATE",
"object_type": "member",
"source": "SCIM",
"id": "member-live-123-...",
"timestamp": "2024-03-07T18:49:32.760777783Z",
"member": { ... }
}Now, the important thing is that, once the IdP events start syncing to Stytch, these enterprise apps have to ensure their application reacts appropriately to user and group changes. For instance, if an employee’s account is de-provisioned from the IdP (e.g., Okta), all internal systems and service providers that the employee had access to must immediately terminate their session and deny access on their next request.
The only way to achieve this is by setting up a webhook endpoint within the enterprise application and configuring Stytch to send all directory sync events to that endpoint.
In this way, we can be sure that the user in question has been automatically de-provisioned not just on the enterprise application alone, but across all the connected SaaS applications they use within the company. While webhooks are not a mandatory part of the SCIM specification, they must be used in conjunction with SCIM to enhance the functionality and real-time capabilities of the system in this kind of scenario.
Automating IaC workflows
Instead of manually configuring networks and servers for every deployment, IaC (Infrastructure as code) enables DevOps teams to define their entire infrastructure using code. This makes it easier for companies to provision and manage their infrastructure resources in a consistent and repeatable manner.
Popular IaC tools like Terraform, AWS CloudFormation, Azure Resource Manager, and Ansible enable these teams to create and deploy infrastructure components such as virtual machines and load balancers using declarative programming.
Now, you may be wondering how webhooks come into play. Webhooks can be used to reduce the steps required to implement and manage git-centric deployment pipelines and also to launch end-to-end IaC workflows automatically.
In GitOps workflows, the Git repository serves as the single source of truth for infrastructure configuration. As such, when a change is made to the infrastructure code in the Git repository, webhooks can automatically trigger the necessary actions to ensure that the actual state of the infrastructure always matches the desired state defined in the code.
The webhook is typically set up to notify the desired state engine whenever a change is pushed to the Git repository, which then executes the necessary IaC workflows to provision, update, or delete infrastructure resources accordingly. For example, let’s assume a developer pushes a code change to the Git repository that modifies the configuration of a virtual machine. The webhook will detect this change and send the updated code to the desired state engine. The desired state engine then uses an IaC tool like Terraform to apply the changes to the virtual machine, ensuring it matches the desired state defined in the code.
Webhooks can also be used to trigger other types of automation beyond infrastructure provisioning. For instance, webhooks can be integrated with CI/CD pipelines to automatically run tests, build artifacts, and deploy applications whenever code changes are pushed to the Git repository. This enables a fully automated workflow where code changes trigger the entire pipeline, from infrastructure provisioning to application deployment.
Common webhook vulnerabilities
If you’re thinking about using webhooks for your application or within your dev team, there are a few common vulnerabilities you’ll need to plan for, the most significant of which are server-side request forgery and replay attacks.
Server-side request forgery (SSRF)
Server-side request forgery (SSRF) is a critical security vulnerability that allows attackers to manipulate web applications or APIs into performing unauthorized actions on their behalf. SSRF attacks can be particularly dangerous because they allow attackers to access internal systems and services that aren’t directly exposed to the internet in order to exfiltrate data or launch denial-of-service attacks.
Webhooks are susceptible to SSRF attacks because they allow consumers to specify custom URLs where they want to receive event notifications. If not properly secured, attackers can manipulate these webhook URLs to point to internal services or resources, effectively using the webhook system as a proxy to perform unauthorized actions.
For example, if a web application allows users to enter custom webhook URLs without proper validation, an attacker could input a URL pointing to an internal service instead of a legitimate external endpoint. As such, when the webhook is triggered, the server will send a request to the specified internal URL, potentially exposing sensitive information or enabling the attacker to interact with internal services.
To prevent SSRF attacks when dealing with webhooks and other server-side requests, one effective approach is to use a proxy server that filters out requests to internal IP addresses and restricts access to sensitive resources. By placing this proxy server between the webhook system and the external network, we can prevent webhooks from directly communicating with internal services.
Additionally, implementing strict input validation and whitelisting for webhook URLs can help mitigate the risk of SSRF attacks. By maintaining a whitelist of trusted domains and IP addresses from which the consumer should accept webhook requests, you can automatically reject any requests from domains or IPs that aren’t on this whitelist.
Replay attacks
Replay attacks happen when a malicious actor intercepts a legitimate webhook request and then resends it to the consumer server at a later time, attempting to trick the server into executing the same action multiple times. This can occur even when the original webhook payload is encrypted or signed, as the attacker doesn’t need to modify the request to cause harm.
This vulnerability arises when webhooks are not designed to be idempotent, meaning that processing the same request multiple times can lead to unintended consequences. For example, if a webhook is used to process a purchase event, a replay attack could result in the purchase being duplicated, leading to incorrect inventory levels, balance discrepancies, or other issues.
To protect webhooks against replay attacks, a common best practice is to include a timestamp in the signature of the webhook payload. The timestamp is typically hashed together with a secret key and the request body, creating a unique signature for each request. When the receiving application processes the webhook, it can compare the timestamp in the signature to the current time. If the timestamp is too old (beyond a predefined threshold), the application can safely reject the request, knowing it’s likely a replayed message.
This approach fortifies against replay attacks because the timestamp cannot be manipulated without invalidating the entire signature. Even if an attacker intercepts a valid webhook request, they cannot modify the timestamp to make it appear current without possessing the secret key used in the signing process.
Wrapping up
We’ve successfully explored the fundamentals of webhook architectures, their real-world use cases, and the most critical security risks and vulnerabilities. However, these vulnerabilities in no way diminish how useful webhooks can be.
To start building auth with Stytch, check out our documentation and sign up for a developer account. If you have any questions, please don’t hesitate to contact us at support@stytch.com.
Build auth with Stytch
Pricing that scales with you • No feature gating • All of the auth solutions you need plus fraud & risk


Authentication & Authorization
Fraud & Risk Prevention
© 2025 Stytch. All rights reserved.