Back to blog
Detecting AI agent use & abuse
Auth & identity
Feb 15, 2025
Author: Reed McGinley-Stempel
AI agents aren’t just indexing your content anymore. With tools like OpenAI’s Operator, Anthropic’s Computer Use API, and BrowserBase’s Open Operator, these agents can navigate the web, mimic real users, and even take actions at scale. The challenge? Knowing whether they’re enhancing your user experience—or opening the door to abuse.
In some scenarios, apps might encourage agent use if it improves usability and adoption, but in other cases, it could present unacceptable risks for application developers or be used as a method for malicious attacks (e.g. credential stuffing or fake account creation).
In either scenario, observability is paramount. Applications need to know what traffic is on their site (is this a human? A bot? A good bot or a bad one?) in order to make intelligent decisions about how to shape traffic and enforce desired usage patterns. AI agents add an additional wrinkle as users are already sharing their credentials with tools like Operator, meaning even a well-intentioned agent creates potential risk for these applications and their users.
The key question is: Can you detect AI agent traffic on your application today?
We tested multiple AI agent toolkits across high-traffic consumer sites, and the results were clear—legacy detection techniques (CAPTCHAs, IP blocking, user-agent filtering) are largely ineffective. Here’s what we found.
The new reality of bot traffic: What AI agent traffic looks like
Traditionally, bot detection relied on CAPTCHAs, IP blocking, and user-agent filtering. But modern AI agents are engineered to look like actual users:
- Realistic fingerprints: They use genuine IP addresses, user agents, and even simulate mouse movements.
- Headless browsing at human speeds: Their interactions mimic natural browsing behavior, evading rate-limit triggers.
- Datacenter origins—but not always: While some (like OpenAI’s Operator) come from known Azure datacenters, others (like Anthropic’s API) can run locally, borrowing your machine’s properties.
On the surface level, AI agent traffic can look quite similar to regular human user traffic. Here are examples of browser & network properties across different AI agents:
Open AI Operator | Anthropic Computer Use API | BrowserBase Open Operator | |
|---|---|---|---|
User Agent | |||
User Agent | Chrome on Linux (standard fingerprint) | Firefox on Ubuntu (stable, unless run locally) | Chrome on Mac (with stealth features) |
IP Address | |||
IP Address | Known Azure Datacenter IP | Varies—depends on local vs. cloud deployment | Known AWS Datacenter IP |
Browser Version | |||
Browser Version | Chrome 130 | Firefox 128 | Chrome 124 |
Location | |||
Location | San Francisco, California | San Jose, California | Boardman, Oregon |
ASN | |||
ASN | 8075 | 398391 | 16509 |
ASN Name | |||
ASN Name | Microsoft | Perimeter 81 | Amazon |
Detection Difficulty | |||
Detection Difficulty | Easy | Harder | Moderate |
Both OpenAI’s Operator and BrowserBase’s Open Operator spin up remote datacenter or container‑hosted Chromium instances, rather than installing any software on your local machine. Because these solutions originate from a cloud‑hosted environment (with IP addresses and other signatures tied to the provider’s infrastructure), they can be easier to detect via methods like ASN lookups if the provider’s IP ranges are well known.
By contrast, Anthropic’s “Computer Use” functionality is available only through its API as of now, and you can choose how to run that API (e.g., directly on your own machine vs. inside a VM or container). If you run it locally, it inherits your local system’s properties like IP and ASN; if you host it in the cloud, it uses whichever environment that provider offers. Each approach has its own implications for fingerprinting and detection.
Currently, Anthropic provides two options for using their agent:
- Direct use of your computer environment (not recommended due to security concerns around unrestricted access).
- Setting up a virtual machine or container with minimal privileges to run the API. You can either run this locally or deploy to a cloud provider using Docker, in which case it won’t inherit the user’s network properties.
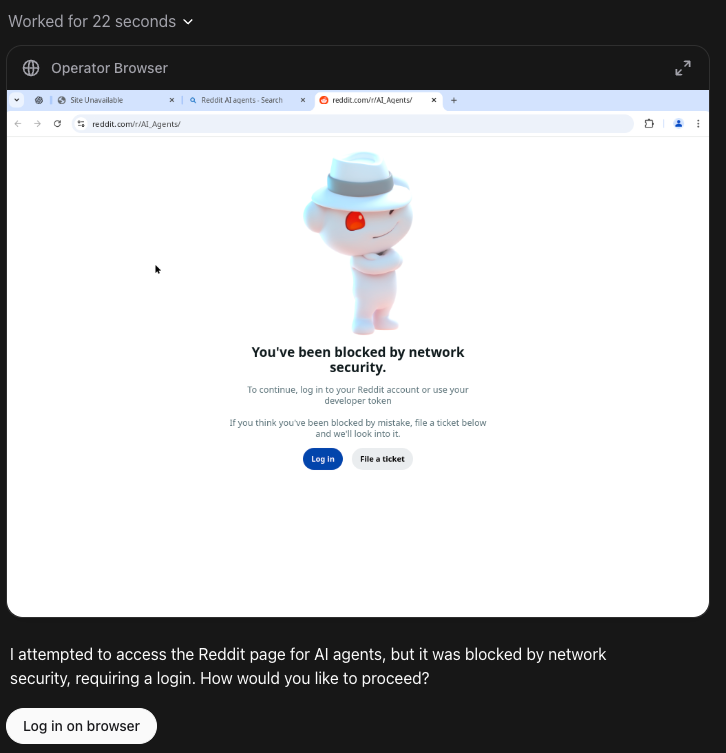
Whereas stricter sites like Reddit block OpenAI and BrowserBase outright, Anthropic’s approach allows it to successfully bypass even these strict sites when run locally:
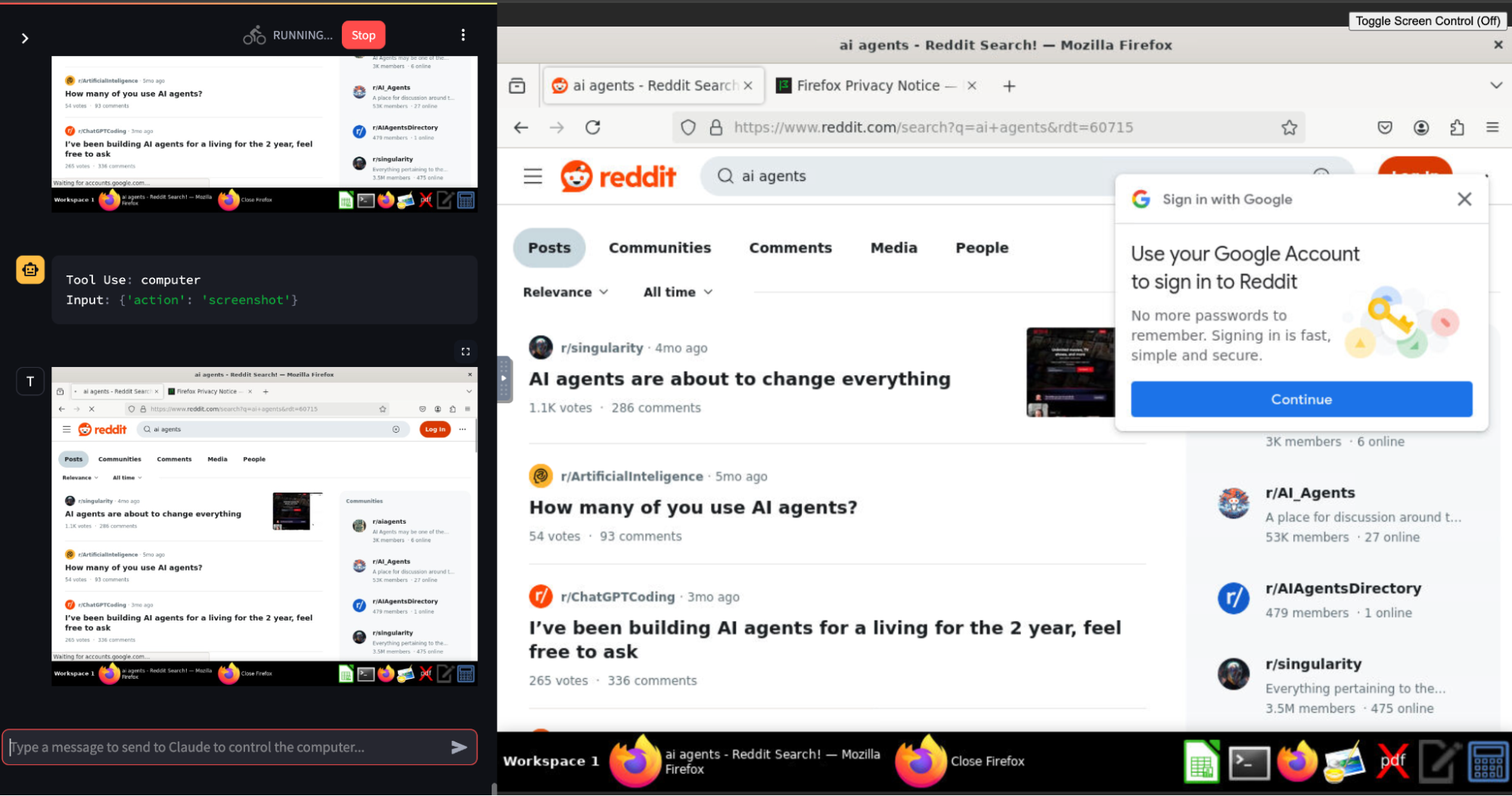
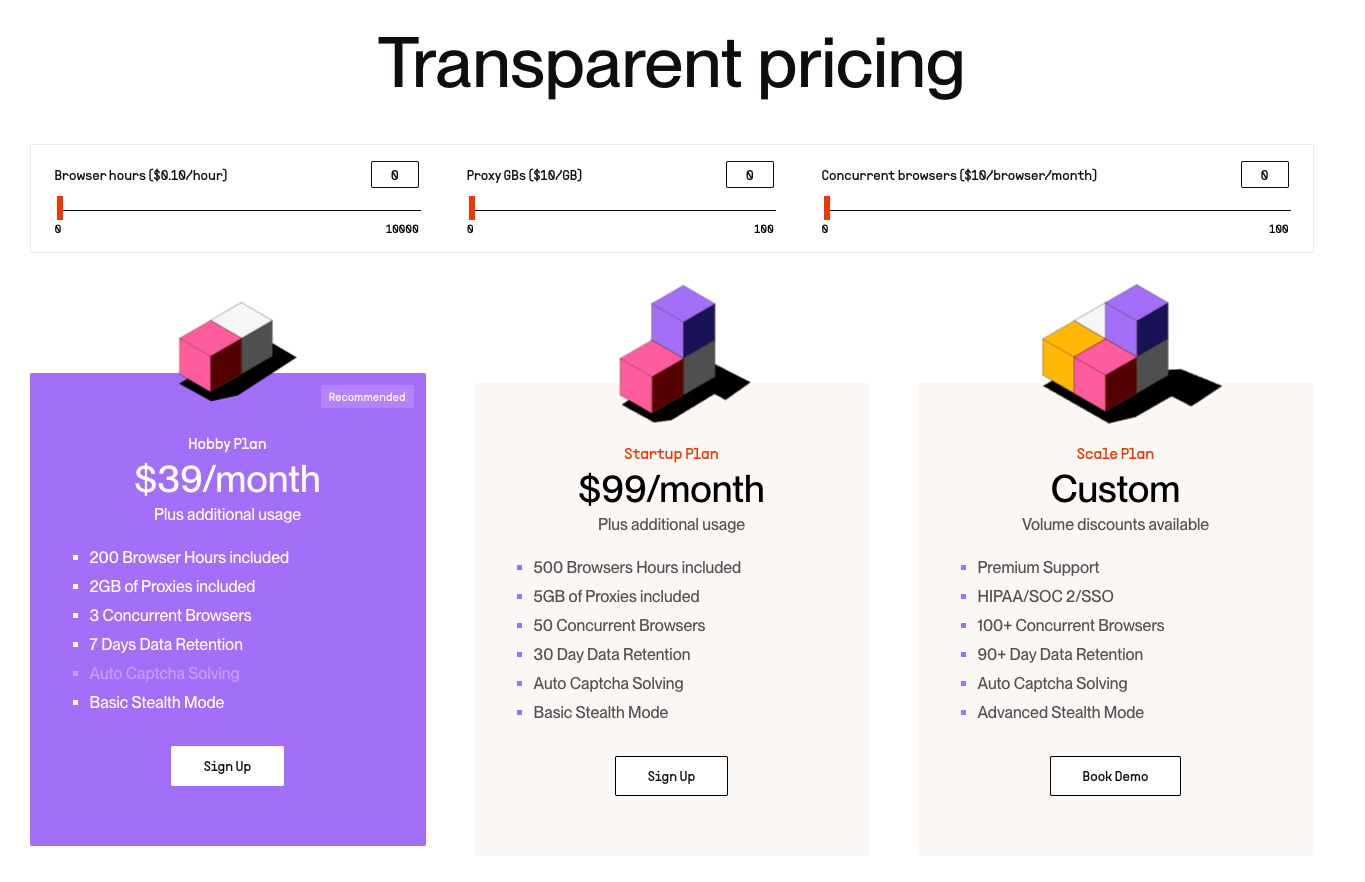
And with tools like BrowserBase, there are also now open-sourced options for building browsing AI agents that allow potential attackers to increase the stealth of their headless browsing setup. This means we should expect continued, quick iteration on some agent use cases that will make them even more difficult to detect. As an example, BrowserBase offers premium plans with more advanced stealth to bypass CAPTCHA and other detection techniques:
Today, most sites are allowing agent traffic to navigate freely – whether these sites are detecting the abnormalities of this traffic (and choosing not to take action) is hard to say. For some like Reddit & Youtube, their block on OpenAI Operator indicates they want to lock down agentic traffic. When these AI Agents bypass their restrictions (as detailed below), it’s a good signal those tools are actually flying below their radar today versus being officially sanctioned.
For others that allow this traffic, they may actually encourage it for user convenience or potentially have perverse incentives in some cases to allow a certain amount of bot traffic (Ticketmaster is a potential example of this given they can benefit from some level of bot activity increasing ticket purchase rates). Many more sites, however, simply don’t have the traffic intelligence to detect these AI agents, which explains why they can operate freely.
In testing the three primary AI Agent browsing toolkits on a set of high traffic consumer sites, we found that Youtube and Reddit were the only ones that consistently blocked this traffic:
OpenAI Operator | Anthropic Computer Use API | BrowserBase Open Operator | |
|---|---|---|---|
Youtube | |||
Youtube | ❌ | ✅ | ✅ |
❌ | ✅ | ❌ | |
✅ | ✅ | ✅ | |
Twitter/X | |||
Twitter/X | ✅ | ✅ | ✅ |
Facebook.com | |||
Facebook.com | ✅ | ✅ | ✅ |
OpenTable | |||
OpenTable | ✅ | ✅ | ✅ |
✅ | ✅ | ✅ | |
Nike | |||
Nike | ✅ | ✅ | ✅ |
Few websites are blocking popular AI Agents today – indicating either a lack of detection, ambivalence towards enforcement, or both. Reddit & Youtube are a couple of key outliers that block this traffic when they can discern it.
Still, the differences are interesting. It’s worth understanding why Anthropic or BrowserBase are sometimes able to bypass sites that otherwise are blocking this traffic. In BrowserBase’s case, they generate a slightly different user-agent each session, which sometimes aligns with the underlying chromium runtime but sometimes attempts to be deceptive by claiming to be a different version, which leads to more inconsistency in whether companies detect it correctly.
Companies like LinkedIn and X are particularly sensitive to scraping on their sites, so the lack of enforcement is surprising. This suggests they’re not currently able to confidently discern this is programmatic traffic.
How to tell an agent from a human
The obvious question here is: shouldn't this be easy to detect by using just an IP or user agent?
And the answer is yes and no. For OpenAI Operator, it’s pretty straightforward to detect given its stability & origin point. For Anthropic and BrowserBase (and the new agents entering the market), it’s a bit more complicated.
OpenAI Operator | Anthropic Computer Use API | BrowserBase Open Operator | |
|---|---|---|---|
Browser Stack | |||
Browser Stack | Chromium | Firefox | Chromium |
IP address properties | |||
IP address properties | Known Azure Datacenter | Depends on how you run it:
| Known AWS Datacenter |
IP stability | |||
IP stability | Remains stable | Remains stable | Churns |
User Agent | |||
User Agent | Remains stable | Remains stable | Churns |
CAPTCHA handling | |||
CAPTCHA handling | Hands off to user | Hands off to user | Offers options for automatically solving |
Some key elements worth knowing:
- OpenAI & BrowserBase both operate on top of chromium – being able to discern chromium browsers vs. true chrome is key for detecting the latter since BrowserBase modifies things like IP, user agent, etc for increased stealth.
- OpenAI originates out of a known Azure datacenter while BrowserBase originates from a known AWS datacenter.
- OpenAI hands off non-invisible CAPTCHAs to the end user to complete, while BrowserBase offers options for automatically solving.
Ideally, you want to detect this traffic beyond more coarse identifiers like known datacenter IPs so that your detection is fully resistant to adjustments agentic traffic will make in the future. And core to that is having high confidence in whether a browser interacting with your site is a real browser or a headless instrumentation.
This is where we’ve personally found Machine Learning to be incredibly useful by building a browser lie detector. We look at a very wide range of browser signals & we have downloaded the entire historical archives of every browser version that has been released that we can find and trained our model on what authentic browsers look like vs. anomalous or deceitful browsers.
To provide this visibility, we’ve automated additions of new legitimate browser signatures upon new releases, we fingerprint it, run it past the model to establish an authentic set of signals for the current browser version, allowing us to detect anyone trying to emulate that version inorganically. With that fingerprinted dataset, machine learning can be used to detect anomalies with high accuracy. It’s this signal collection that has allowed us to see that OpenAI & BrowserBase are full chromium builds, while Anthropic’s Firefox browser fails to emulate certain characteristics that would be present on a real user’s Firefox instance.
Charting your path forward
Whether you choose to block, restrict, or harness AI agent traffic, effective observability is non-negotiable. Here’s our current playbook:
- Monitor actively: Start by detecting and monitoring AI agent fingerprints. Learn from their behavior before enforcing hard limits.
- Embrace legitimate use cases: Some users may leverage AI agents to streamline workflows (e.g., automating reporting on your dashboard). Recognize these opportunities while safeguarding against abuse.
- Iterate quickly: As AI agents evolve, so must your detection strategies. Invest in ML-based solutions that adapt alongside new agent behaviors.
AI agents are rewriting the rules of web interaction. They offer exciting UX advancements—but also present new security challenges. The race is on: evolve your detection or risk being outpaced by bad actors and unintended misuse.
If you’re interested in learning more about how to detect these agents & enforce certain behaviors, reach out to us to chat more (or take a look at the fingerprinting techniques we’re using to detect them).
Try Device Fingerprinting
99.99% bot detection, intelligent rate limiting, and reverse engineering protection.

Authentication & Authorization
Fraud & Risk Prevention
© 2025 Stytch. All rights reserved.