Back to blog
How to block AI web crawlers: challenges and solutions
Auth & identity
May 21, 2025
Author: Reed McGinley-Stempel
Recent advances in generative AI make it possible for companies to crawl vast swaths of the internet to feed their models with training data. Unlike traditional search engine bots that index content and drive traffic back to sites, these AI-focused web crawlers often scrape proprietary or user-generated content without direct benefit to the owner while consuming considerable resources.
This article explores the current landscape of AI web crawlers. It covers who’s running them and how they behave, and it outlines the technical and non-technical methods you can use to detect and block bots with notable examples of their use.
Table of Contents
- AI web crawlers: Who runs them and why?
- How companies are responding to AI scraping
- Do AI crawlers respect
robots.txt? - How to block AI web crawlers
- Challenges with crawler evasion and enforcement
AI web crawlers: Who runs them and why?
AI web crawlers operated by major tech companies and startups are scouring the internet for data to train their LLMs and other AI systems. Some of the notable players include:
OpenAI (GPTBot and friends)
OpenAI introduced GPTBot in 2023 as its primary crawler to gather text from the web for training ChatGPT and future models. OpenAI also has other agents like ChatGPT-User (for fetching content during chat interactions) and OAI-SearchBot.
Google (Search and Google-Extended)
Google’s standard Googlebot search crawler has indexed the web for decades, but Google has introduced a separate token for AI called Google-Extended to crawl content for its generative AI products like Bard and Gemini. This allows sites to opt out of AI training while remaining indexed in regular search. Google’s GoogleOther crawler is also used for non-search related crawling.
Common Crawl (CCBot)
Non-profit Common Crawl runs CCBot, which regularly crawls billions of pages to produce an open web dataset. Many AI projects (OpenAI, Google, Meta, etc.) rely on Common Crawl’s data. CCBot generally behaves like a broad, search-engine-style crawler, fetching all publicly available pages unless disallowed.
Anthropic (ClaudeBot)
Anthropic, maker of the Claude AI assistant, operates its own web crawlers. AnthropicAI and ClaudeBot user agents are used to collect data for model training. Claude’s crawler reportedly generated hundreds of millions of requests per month in 2024, second only to OpenAI’s GPTBot.
Others
Apple’s Siri uses Applebot and Applebot-Extended to crawl web results for Siri and Spotlight. China’s Huawei runs PetalBot for its own search/AI needs. Smaller AI firms like Cohere (an NLP startup), AI2 (Allen Institute), and Diffbot (a structured data crawling service) also operate crawlers targeting specific data. Even Microsoft’s Bing crawler is now dual-purpose: it scrapes data for search and also to feed Bing Chat / GPT-4 based experiences.
Many bots identify themselves via unique user agent strings, which is the first clue for webmasters looking to manage or block their access. But simply knowing who they are is only half the battle — the big question is whether these bots respect your rules for crawling.
Case study: How companies are responding to AI scraping
With AI companies scraping content en masse, many content platforms and publishers are pushing back, and loudly. This has led to high-profile controversies and shifts in policy over the past two years. Here are some notable developments:
Reddit’s revolt
The forum platform Reddit realized its treasure trove of user discussions was being used to train AI (ChatGPT’s training data famously included Reddit conversations). In 2023, Reddit introduced steep charges for API access, updated its terms to forbid data scraping, and started blocking crawlers that didn’t pay up. Reddit’s CEO Steve Huffman specifically called out Microsoft, OpenAI/Anthropic, and startup Perplexity for “using Reddit’s data for free” and said blocking them has been “a real pain in the ass.”
Twitter/X’s crackdown
Twitter (now X) took an aggressive stance against data scraping in mid-2023 by temporarily blocking all access to tweets for users who were not logged in, as well as limiting how many tweets a user can read, in a move explicitly aimed at stopping scrapers. X owner Elon Musk tweeted that this was a “temporary emergency measure” because “hundreds of organizations” were scraping Twitter data, which was degrading the user experience. Musk has also vocally criticized AI firms like OpenAI for training on Twitter data without permission. Beyond technical blocks, X Corp. took legal action by filing lawsuits against unknown entities believed to be scraping data in violation of the terms.
Stack Overflow & Stack Exchange
The Q&A communities of Stack Exchange (Stack Overflow being the largest) contain millions of user-contributed answers, which are a gold mine for training coding AIs and chatbots. Acknowledging this, Stack Overflow initially added rules to ban AI crawlers. In late 2023, their robots.txt explicitly disallowed OpenAI’s GPTBot, Amazon’s crawler, and others. They also asserted that content is licensed (CC BY-SA), so any AI usage must comply with attribution/share-alike (which wasn’t happening).
Interestingly, by March 2024, Stack Overflow removed the block on GPTBot, possibly hinting at discussions or a partnership with OpenAI. Stack Overflow’s engineering team also shared how they fight scrapers using advanced bot detection, Cloudflare tools, and analyzing patterns like identical TLS fingerprints across many connections. They’ve observed scrapers creating many accounts (sometimes even paying for accounts) to blend in as “real” users, demonstrating the constant battle to allow genuine usage (for example, developers browsing questions) while stopping mass harvesting.
News media vs AI
Many news organizations have moved to block AI crawlers and even pursue legal remedies. The New York Times updated its robots.txt in mid-2023 to disallow OpenAI’s GPTBot, and shortly after it was rumored to be considering a lawsuit against OpenAI for copyright infringement. Other outlets like CNN, Reuters, and The Guardian also blocked GPTBot.
The Associated Press chose a different route: it struck a deal to license its news archives to OpenAI in exchange for access to OpenAI’s technology, one of the first licensing deals of its kind. By late 2023, over 50% of major news sites had some form of block in place against AI crawlers. There are also legal suits filed by authors alleging that AI models infringed copyrights by training on pirated copies of their books. This legal landscape is evolving, but it’s clear that content creators, from news writers to artists to coders, are pushing back on unauthorized scraping.
Code and art datasets
There’s not just controversy in text, but in code and image domains too. GitHub’s Copilot was trained on public GitHub code, which led to a lawsuit claiming it violated open-source licenses. Meanwhile, image generators like Stable Diffusion were trained on billions of web images, spurring lawsuits from artists and photo agencies. These cases underscore the legally undecided issue of whether training AI on publicly accessible data is allowed and whether creators deserve a say (and a share in the profits).
Initially, AI labs grabbed whatever data they could access without permission or consideration for its owners or creators, operating under the tech mantra of “move fast and break things” (or perhaps better phrased in this case, "move fast and scrape things"). Now, from lone artists to giant platforms, content owners are fighting back and asserting control over their data. We’re witnessing the negotiation of a new balance: how to enable AI innovation without simply pillaging the work of millions of creators.
Do AI crawlers respect robots.txt?
Traditional search engine crawlers like Google and Bing have long honored the rules you set in your robots.txt file. But do AI web crawlers follow robots.txt? The answer is a resounding… sometimes.
On paper, most major AI companies claim to respect robots.txt:
- OpenAI has published instructions for webmasters on how to disallow GPTBot via robots.txt, implying that it obeys those rules.
- Anthropic stated that Claude’s crawler abides by standard crawler exclusions.
- Google’s AI crawling (Google-Extended) explicitly uses robots.txt as an opt-out mechanism for sites that don’t want to be used in AI training.
- Non-profit Common Crawl also honors robots.txt. If your site disallows CCBot, Common Crawl should skip it during their scans.
However, as robots.txt is a voluntary standard with no enforcement mechanism, any crawler can ignore it. A recent investigation revealed that OpenAI and Anthropic were bypassing robots.txt directives on news publisher sites. TollBit, a startup that analyzes publisher logs, found multiple AI agents crawling restricted content despite explicit blocks. OpenAI’s response was noncommittal, saying only that they “take crawler permissions into account” when training models — far from a promise to respect rules at crawl time.
They’re not alone. It was recently reported that Perplexity AI’s crawler was caught ignoring robots.txt on Forbes.com. Broader data suggests that numerous AI crawlers routinely bypass the protocol across many publishers. In a survey of 1,158 news sites, more than half attempted to block OpenAI, Google AI, or Common Crawl, yet many of those sites were still crawled. Clearly, not all bots are playing by the rules, and people aren't happy about it.
The simple answer to why a company would risk its reputation by ignoring the wishes of content creators and owners is data hunger. The most valuable content (social media conversations, forums, news archives, etc.) often resides behind paywalls or explicit disallow rules. With billions of dollars at stake in building the best AI, some actors have decided that the informal rules of the web are worth skirting for a competitive edge. Also, enforcement is tricky, and unless a site takes legal action, a rogue crawler faces little immediate consequence.
How to block AI web crawlers
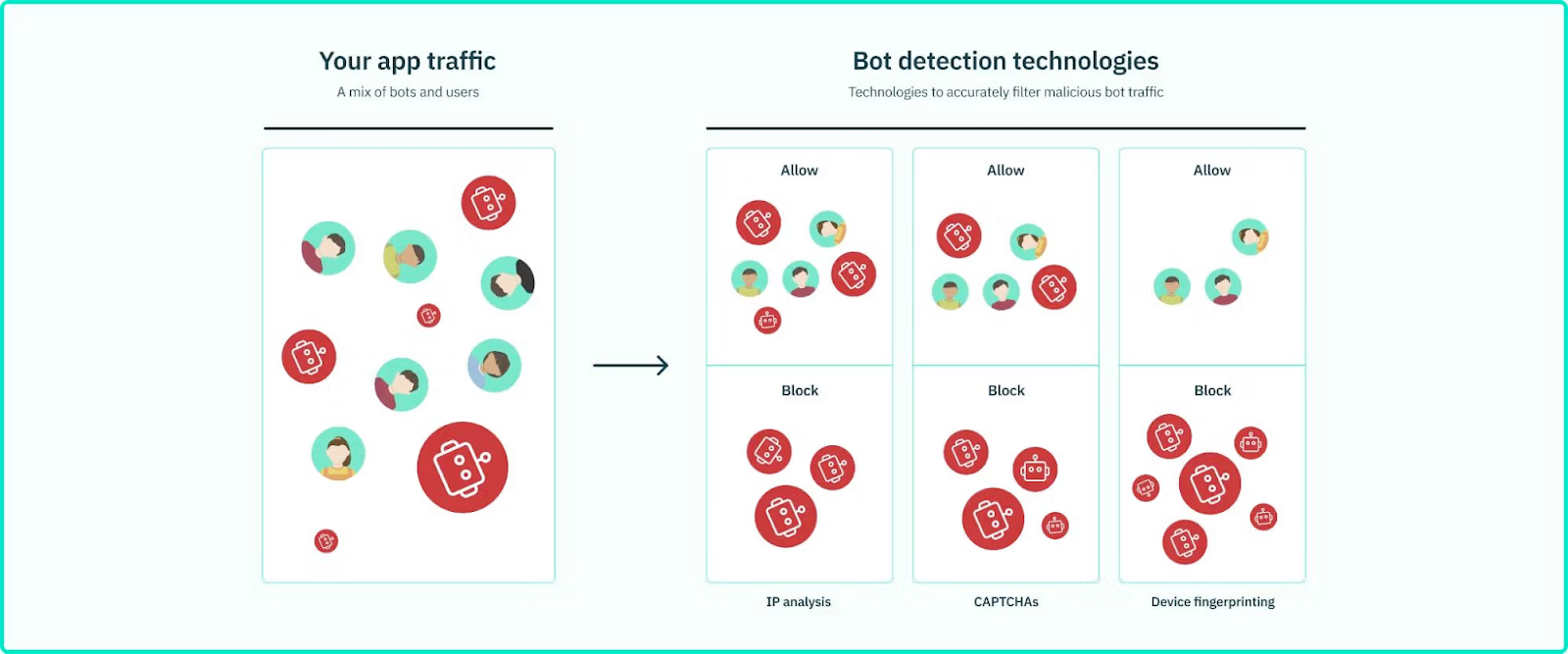
There are several established technical methods you can use to block AI scrapers. Because each comes with pros, cons, and varying levels of effectiveness, a layered approach that combines multiple defenses is most effective.
Disallow rules in robots.txt
The first and simplest tool is still robots.txt. By adding disallow directives for known AI user agents, you can (politely) ask those bots to stay out. For example, to block OpenAI’s GPTBot you would include the following in your robots.txt file:
User-agent: GPTBot
Disallow: /Similar rules can block crawlers like ClaudeBot, AnthropicAI, CCBot, Google-Extended, and PetalBot. This solution is easy to implement and often effective when dealing with above-board companies. For instance, after OpenAI announced GPTBot, hundreds of major sites (such as Reddit, Wikipedia, and The New York Times) promptly disallowed it, and GPTBot’s traffic respected those instructions.
Limitations: robots.txt is voluntary, and malicious (or “rogue”) scrapers will simply ignore it. It’s a necessary line of defense but far from sufficient. Think of it as putting up a “No Trespassing” sign — it deters the honest but doesn’t physically stop a determined intruder. Also, maintaining the list of bot user agents can be a chore, as new crawlers emerge frequently.
User agent filtering
Going a step farther, you can configure your web server or firewall to outright block or redirect certain user agents. This means if a request comes in claiming to be from GPTBot/1.0 or ClaudeBot/1.0, you can refuse to serve the page (or serve a dummy page). Unlike robots.txt that relies on the bot to self-regulate, user agent filtering is enforced on your side.
Most HTTP servers and CDNs have user agent-filtering capabilities, and it is usually straightforward to implement. It was used by Stack Overflow initially to block OpenAI’s GPTBot and is an effective second line.
Limitations: User agent strings are easily and commonly spoofed. A scraper can avoid detection by pretending to be a normal web browser (for example, sending a fake "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0" string). So, user agent filtering will catch only the well-behaved bots that correctly identify themselves and won’t stop a covert scraper that masquerades as Chrome or Safari. Think of it as checking IDs at the door — helpful, but fake IDs are easily obtained.
IP address blocking
IP-based blocking or rate limiting can be implemented if you are able to identify the IP ranges or hosting providers used by scrapers. For example, if you notice a flood of scraping from AWS or Azure cloud servers, you might block those cloud provider IP ranges entirely from accessing your site (provided legitimate users for your service don’t typically come from them).
Some large publishers have taken to blocking cloud data center IPs by default, since many DIY scrapers run from cloud VMs. You can also use firewalls or services to dynamically block IPs that make too many requests too quickly.
Limitations: Determined scrapers can evade IP blocks by using proxies or VPNs. They can also cycle through IP addresses (even residential IP proxies) to avoid detection. IP blocks also risk collateral damage — you might accidentally block real users who share an IP or who use a VPN. It’s a blunt instrument that works best for known “bot swarms” coming from specific hosts, but it is less effective against widely distributed scraping and bots that constantly hop IPs.
Rate limiting and throttling
Setting up rate limits on your server or API can slow down scrapers. Legitimate human users rarely load dozens of pages per second, but a bot often will. By capping the rate, you can mitigate the impact of a scraper (or make it so slow that it’s not worth their effort).
Many web application firewalls (WAFs) and CDNs offer rate limiting rules. Even simple strategies like exponentially increasing response times after successive requests can deter bots.
Limitations: Sophisticated bots know how to distribute their requests to fly under the radar. A scraper could use a hundred different IPs, each staying just below your threshold to circumvent the limit. Rate limiting is still a valuable tool to reduce load (Twitter’s massive read-limit in mid-2023 was an extreme example of this, aimed at curbing “extreme levels” of scraping), but by itself, rate limiting won’t catch a clever, patient botnet.
Honeypots and tarpits
A clever defensive trick is setting honeypots or tarpits: traps that only bots would fall into.
A simple honeypot might be a hidden link or form field on your page (made invisible to humans via CSS) that legitimate users won’t interact with, but a bot crawler might. When the bot has interacted with the trap, you've caught and identified it, and can then block it.
A more aggressive approach is a tarpit: serve an endless, resource-draining page to suspected bots. Tools like Nepenthes dynamically generate an infinite maze of junk links that a bot will follow indefinitely. The goal is to waste the crawler’s time and resources (and possibly pollute their AI dataset with garbage). Some hope that feeding AI scrapers gibberish data will deter them altogether, or at least degrade the quality of the AI models trained using the scraped data.
Limitations: Tarpits can backfire. They still consume your server resources, and they might ensnare bots that you do want to accurately navigate your website (such as search engine bots). Tarpits are an experimental, somewhat adversarial technique that act as a form of protest as much as protection, and their effectiveness is debatable, as it's reported that OpenAI’s GPTBot learned to escape some Nepenthes traps. Some teams even put a lightweight proof-of-work (PoW) gate in front of every request—open-source projects like Anubis issue a short hash-puzzle that humans solve invisibly but forces high-volume scrapers to burn CPU time, adding real cost to automated harvesting.
Requiring authentication or payment
One highly effective way to stop unwanted crawlers is to put your content behind a login or paywall. This isn’t feasible for every site (and it goes against the ethos of an open web), but some platforms have chosen this route.
By requiring API keys, login tokens, or payments, you can assert more control over access. For example, Reddit dramatically raised the price of its API access in 2023 specifically to charge AI companies for data. Twitter (now X) similarly cut off free API access and even temporarily required login for all web viewing to thwart scrapers.
Limitations: While these measures can be effective, they also inconvenience regular users and developers. It’s a drastic step that typically comes as a last resort when monetization of data is a priority.
Advanced device fingerprinting
While the methods we’ve discussed so far can create barriers to more basic bots, they tend to either operate on easily spoofed signals or come with tradeoffs for legitimate users. This is where device fingerprinting comes in.
To catch stealthy bots that deliberately mask their identity, you can detect them using modern device fingerprinting and behavioral analytics that focus on how a visitor acts, rather than just who they claim to be.
When a real user visits your site, their browser runs JavaScript, loads images, and produces certain patterns (mouse movements, timing between clicks, etc.) A headless scraping script may not exhibit these behaviors, or might have other subtle tells like missing certain browser APIs or a peculiar TLS handshake signature.
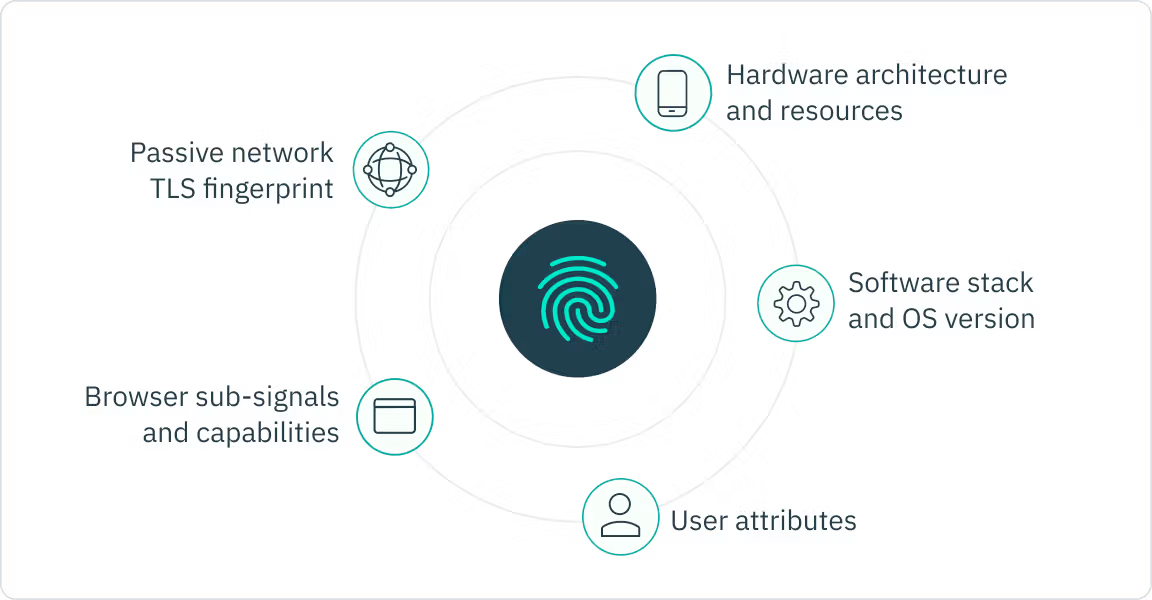
Device fingerprinting tools, such as those offered by Stytch, can gather dozens of signals (including browser version, screen size, OS, installed fonts, JA3 TLS fingerprint, and others) to create a unique device fingerprint. Then, when a visitor is identified as a bot, they can be blocked based on this fingerprint rather than other broad or easily spoofed identifiers.
Challenges with crawler evasion and enforcement
Even with all the above techniques, determined crawlers can be hard to completely block. Those that build AI scrapers have their own toolbox of evasion techniques to counter them, that they also use in a layered approach:
- User agent spoofing: A bot can pretend to be a normal browser or even impersonate another bot that you trust, making user agent filtering unreliable.
- IP rotation: By cycling through IP addresses (sometimes hundreds of thousands via botnets or proxy networks), scrapers can evade IP-based throttles. Each IP makes only a few requests, allowing it to fly under the radar.
- Headless browsers and human mimicry: Modern scrapers may run real browser engines (Chrome Headless, Puppeteer, etc.) to execute JavaScript, defeat simple browser fingerprinting, and even simulate mouse movements or random delays. They might also solve CAPTCHAs using AI or farms of low-paid humans. Some operations go as far as using human botnets, coordinating many real users or compromised accounts to scrape data manually or semi-manually.
- Stealth and adaptation: If a bot gets blocked, its operators can quickly tweak its fingerprint or behavior and try again in a game of cat-and-mouse with your bot detection technologies. High-value scrapers will test your defenses, find weak spots, and adapt. For instance, if they notice you block all AWS IPs, they might switch to residential proxies, or if you rely on a certain fingerprint property, they’ll randomize it.
From the defender’s perspective, one major challenge is false negatives vs. false positives. You want to block all bots, but aggressive blocking (blocking large IP ranges, strict fingerprint rules, etc.) can accidentally lock out real users. On the other hand, if you loosen the rules to avoid false positives, some bots will slip through. It’s a delicate balance that requires continuous tuning.
Another challenge is lack of legal or standardized enforcement. If a scraper ignores robots.txt and evades technical blocks, the remaining option is legal action, which is costly and slow and comes with unproven results. Some court rulings have found scraping public data is legal, while others support claims of unauthorized access or contract violation. This uncertainty emboldens AI scrapers who are able to operate in a legal gray area.
Block AI crawlers and scrapers, not users
As AI models get hungrier, we can expect AI crawlers to become more aggressive and sophisticated, putting website owners in a tough spot: how to share content with genuine users and traditional search engines while keeping uninvited AI scrapers at bay. This can be achieved by adopting a mix of policy and advanced technical defenses that can recognize bots by analyzing deep device and network signals, blocking automated agents before they wreak havoc.
The approaches that offer the most comprehensive protection combine multiple layers of defense, and can block AI crawlers without damaging experience for real users. Technologies like Stytch’s device fingerprinting solution aggregate many device and network signals to detect bots and can flag or block them in real time. It can identify when multiple different sessions are actually the same device or script. By integrating these services, developers can get a risk score for each request and decide to allow, block, or challenge it — putting you in control of what kind of users have access to your website and the valuable content on it.
The Wild West days of AI scraping are starting to give way to a more regulated environment, and taking a stance now, whether through technology or policy, ensures you have a say in how your content is used in the AI era.
Authentication & Authorization
Fraud & Risk Prevention
Resources
Community
© 2020-2026 Stytch. All rights reserved.